

Chapter 07 딥러닝을 시작합니다 ▶ 패션 럭키백을 판매합니다!
07-1 인공 신경망 ▶ 텐서플로로 간단한 인공 신경망 모델 만들기
학습 목표
- 딥러닝과 인공 신경망 알고리즘을 이해하고 텐서플로를 사용해 간단한 인공 신경망 모델을 만들어봅시다.
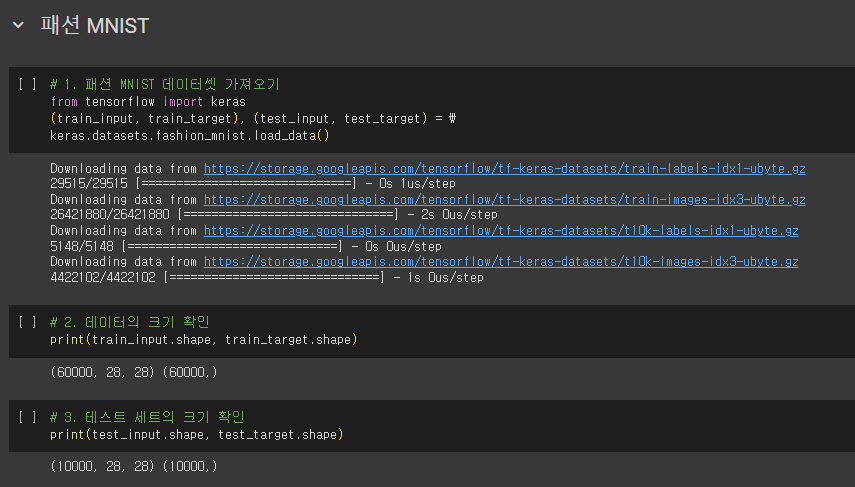
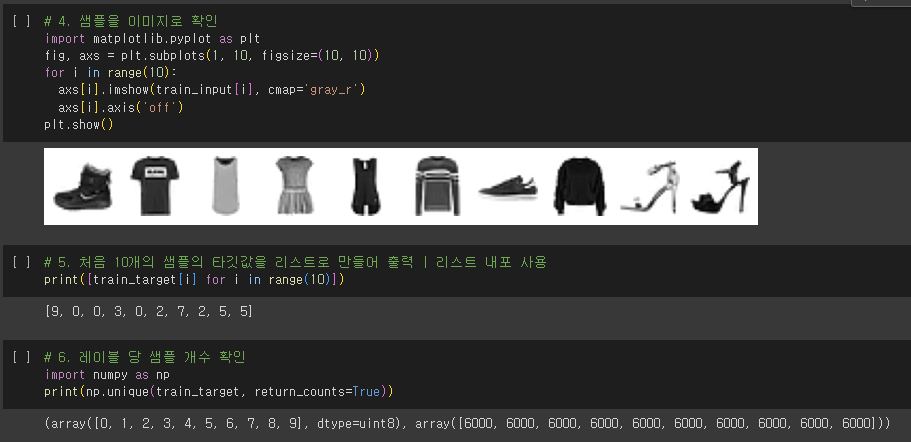
패션 MNIST
- MNIST
- 머신러닝: 붓꽃 데이터셋
- 딥러닝: MNIST 데이터셋
- 손으로쓴 0~9까지의 숫자로 이루어짐
- 패션 MNIST
- MNIST와 크기, 개수가 동일하지만 숫자 대신 패션 아이템으로 이루어진 데이터
- 각 픽셀은 0~255 사이의 정숫값을 가짐
- 이런 이미지의 경우 보통 255로 나누어 0~1 사이의 값으로 정규화
- 이는 표준화는 아니지만 양수 값으로 이루어진 이미지를 전처리할 때 널리 사용하는 방법
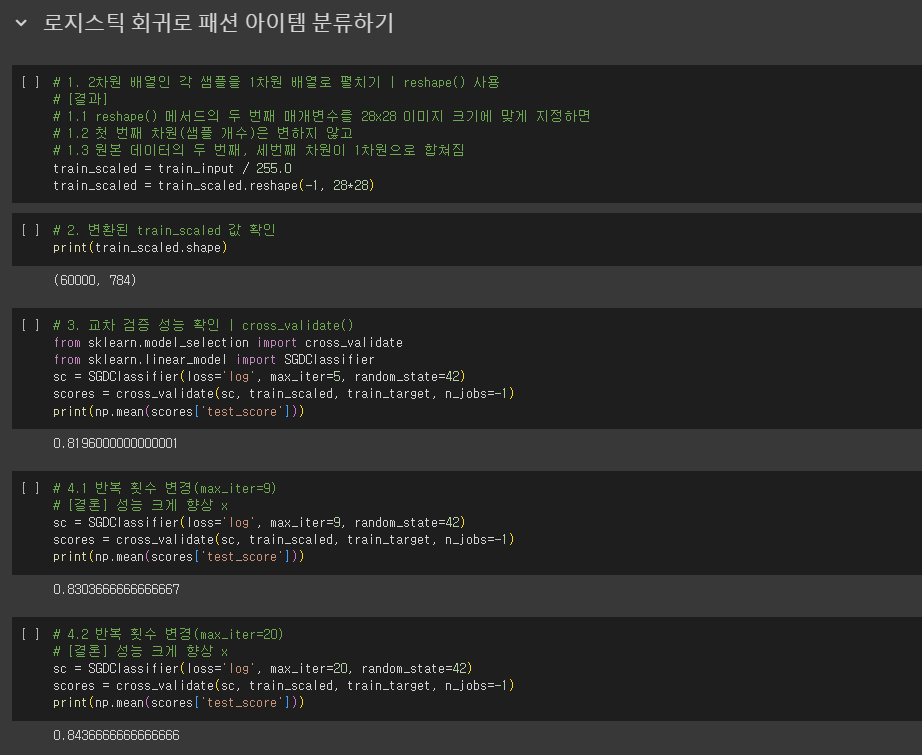
로지스틱 회귀로 패션 아이템 분류하기
인공 신경망
- ANN(Artificial Neural Network)
- 가장 기본적인 인공 신경망 = 확률적 경사 하강법을 사용하는 로지스틱 회귀
- 입력층(input layer)
- 출력층(output layer)
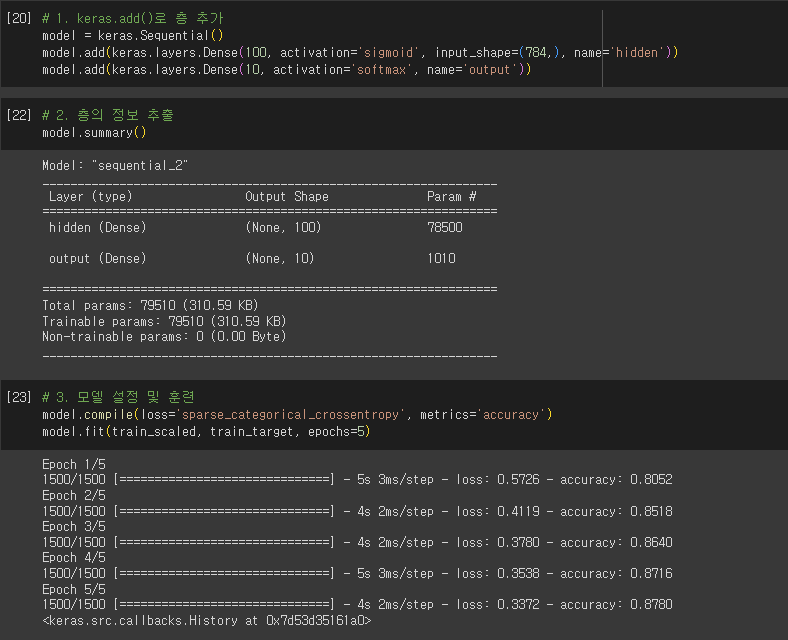
- 뉴런(neuron) = 유닛(unit)
- 인공 신경망에서 z값을 계산하는 단위
- 인공 신경망의 등장
- 1943년, 매컬러-피츠 뉴런
- 기존의 머신러닝 알고리즘이 잘 해결하지 못했던 문제에서 높은 성능을 발휘하는 새로운 종류의 머신러닝 알고리즘
- 딥러닝 = 인공 신경망
- 딥러닝(DNN, Deep Neural Network)
- 심층 신경망: 여러 개의 층을 가진 인공 신경망
- 텐서플로
- 2015년 11월, 구글이 오픈소스로 공개한 딥러닝 라이브러리
- 저수준 API vs. 고수준 API
- 케라스(Keras): 텐서플로의 고수준 API
- 직접 GPU 연산 수행 X
- 대신 GPU 연산을 수행하는 다른 라이브러리 백엔드(backend) 사용
- 케라스의 백엔드
- ex. 텐서플로, 씨아노, CNTK 등 ⇒ 멀티-백엔드 케라스
- 멀티-백엔드 케라스는 2.3.1 버전 이후로 더이상 개발 X
- So, 텐서플로 = 케라스
- 케라스(Keras): 텐서플로의 고수준 API
- 딥러닝 라이브러리와 머신러닝 라이브러리의 차이점
- 그래픽 처리 장치인 GPU를 사용하여 인공 신경망 훈련
- GPU: 벡터와 행렬 연산에 매우 최적화 → 곱셈과 덧셈이 많이 수행되는 인공 신경망에 큰 도움.
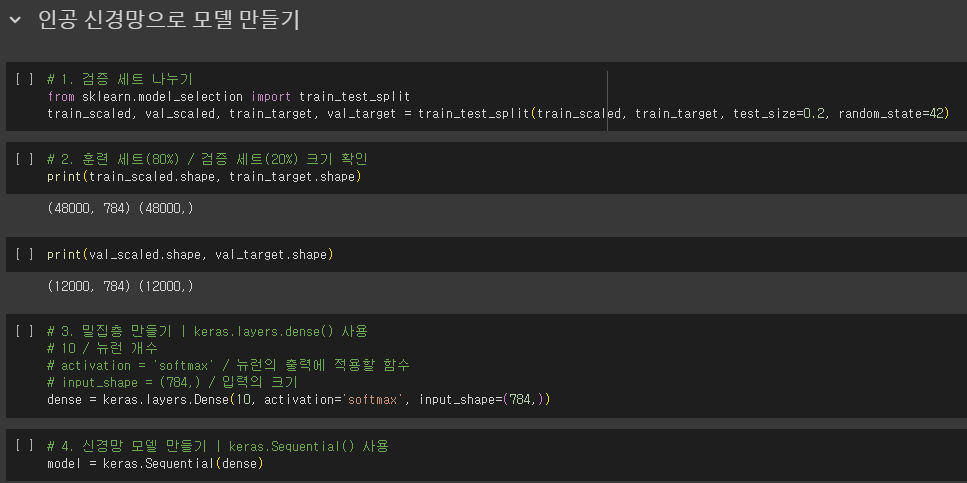
인공 신경망으로 모델 만들기
- 로지스틱 회귀에서는 교차 검증 → 모델 평가
- 인공 신경망에서는 검증 세트를 별도로 덜어 내어 → 모델 평가
- 이유 1. 딥러닝 분야의 데이터셋은 충분히 크기 때문에, 검증 점수가 안정적
- 이유 2. 교차 검증을 수행하기에는 훈련 시간이 너무 오래 걸림.
- 케라스의 레이어(keras.layers) 패키지 안에 층
- 밀집층(dense layer)
- 빼곡하게 연결되어 있으므로(ex. 784 x 10 = 7,840)
- 완전 연결층(fully connected layer)
- 양쪽의 뉴런이 모두 연결하고 있으므로
- 밀집층(dense layer)
- 입력층과 출력층 사이에서 연결선만 표시, 가중치 표시 X
- 절편의 경우는 아예 선도 안그리는 경우 多
- 하지만, 절편이 뉴런마다 더해진다는 사실!
- 활성화 함수(activation function) → a
- 소프트맥스와 같이 뉴런의 선형 방정식 계산 결과에 적용되는 함수
인공 신경망으로 패션 아이템 분류하기
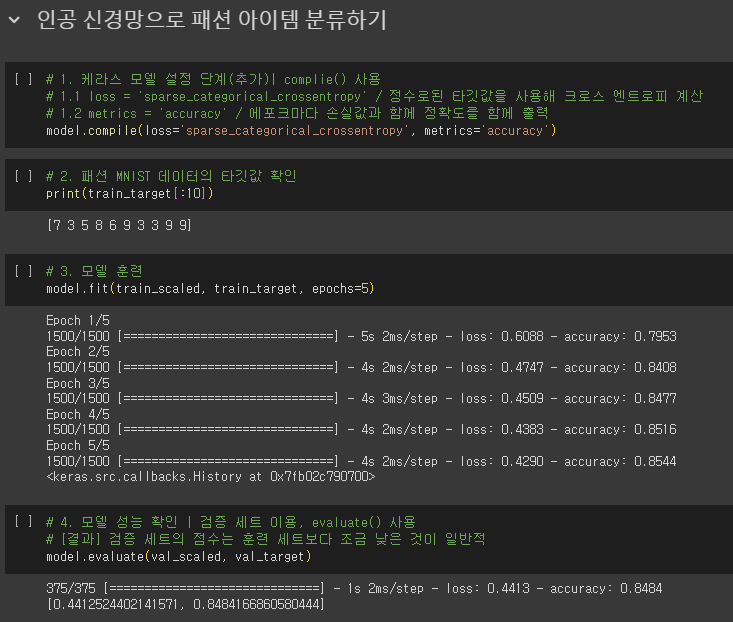
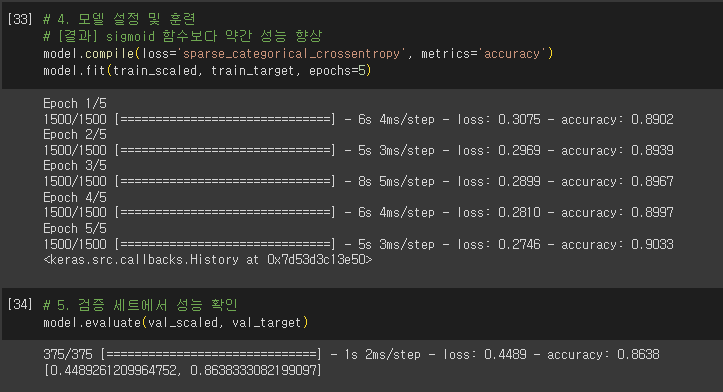
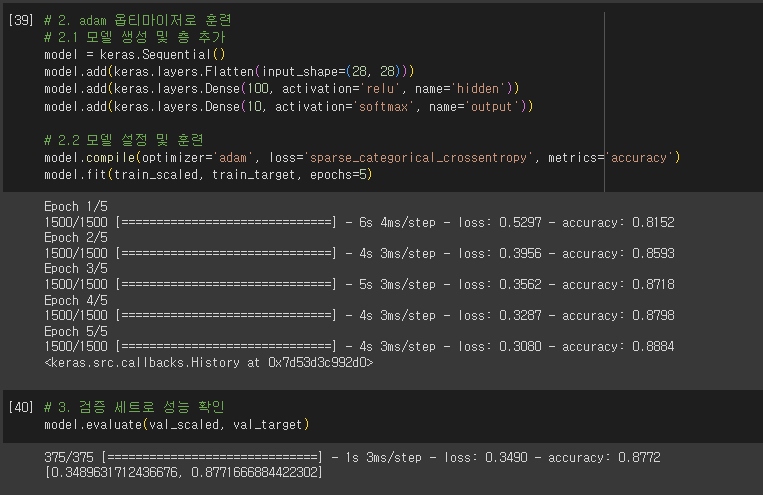
- 케라스 모델 훈련 전 설정 단계
- 손실 함수
- 이진 분류: loss = ‘binary_crossentropy’
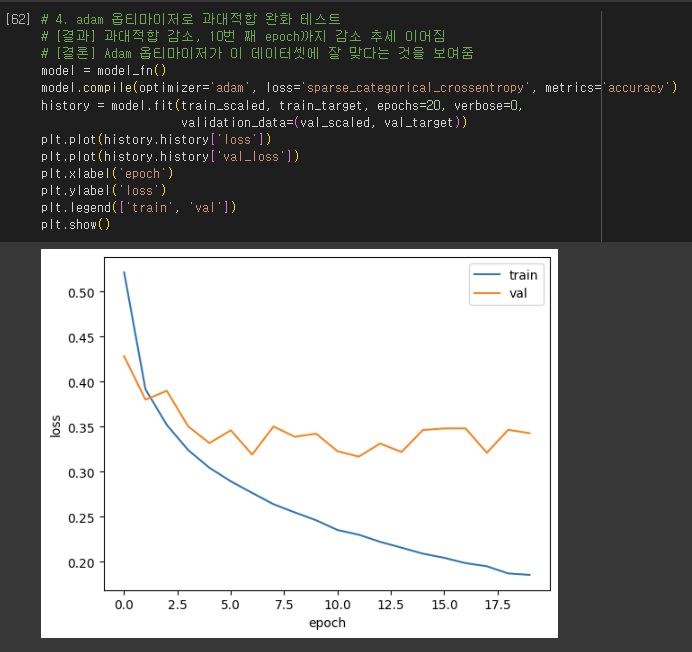
- 다중 분류: loss = ‘categorical_crossentropy’
- 결국 신경망은 티셔츠 샘플에서 손실을 낮추려면 첫 번째 뉴런의 활성화 출력 a1의 값을 가능한 1에 가깝게 만들어야함.
- 크로스 엔트로피 손실 함수가 신경망에서 원하는 바
- 원-핫 인코딩(one-hot encoding)
- 타깃값을 해당 클래스만 1(hot)이고 나머지는 모두 0인 배열로 만드는 것
- 손실 함수
- sprase_categorical_crossentropy
- 정수로된 타깃값을 사용해 크로스 엔트로피 손실 계산
- sprase(희소)
- 케라스
- 모델이 훈련할 때 기본으로 에포크마다 손실 값 출력
- 손실값과 함께 정확도를 함께 확인하기 위해
- metrics=’accuracy’로 지정
핵심 패키지와 함수
- Tensorflow
- Dense: 신경망에서 가장 기본 층민 밀집층을 만드는 클래스
- 첫 번째 매개변수: 뉴런의 개수 지정
- activation 매개변수: 매개변수에 사용할 활성화 함수 지정
- 이진 분류: sigmoid
- 다중 분류: softmax
- default: 사용 x
- input_shape 매개변수: 입력의 크기 지정
- Sequential: 케라스에서 신경망 모델을 만드는 클래스
- 이 클래스의 객체를 생성할 때, 신경망 모델에 추가할 층 지정 가능
- 추가할 층이 1개 이상일 경우, 파이썬 리스트로 전달
- compile(): 모델 객체를 만든 후 훈련하기 전에 사용할 손실 함수와 측정 지표 등을 지정하는 메서드
- loss 매개변수: 손실 함수 지정
- 이진 분류: binary_crossentropy
- 다중 분류: categorical_crossentropy
- 클래스 레이블이 정수일 경우: sparse_categorical_crossentropy
- 회구 모델일 경우: mean_square_error
- metrics 매개변수: 훈련 과정에서 측정하고 싶은 지표 지정
- 측정 지표가 1개 이상일 경울 ㅣ스트로 전달
- loss 매개변수: 손실 함수 지정
- fit(): 모델 훈련 메서드
- 첫 번째 매개변수: 입력 데이터
- 두 번째 매개변수: 타깃 데이터
- epochs 매개변수: 전체 데이터에 대해 반복할 에포크 횟수 지정
- evaluate(): 모델 성능 평가 메서드
- 첫 번째 매개변수: 입력 데이터
- 두 번째 매개변수: 타깃 데이터
- compie() 메서드에서 loss 매개변수에 지정한 손실 함수의 값과 metrics 매개변수에서 지정한 측정 지표 출력
- Dense: 신경망에서 가장 기본 층민 밀집층을 만드는 클래스
확인 문제
- 어떤 인공 신경망의 입력 특성이 100개이고 밀집층에 있는 뉴런 개수가 10개일 때 필요한 모델 파라미터의 개수는 몇 개인가요?
- 정답: 1번 / 1,000개 = 100 x 10 💡 기본 미션
- 케라스의 Dense 클래스를 사용해 신경망의 출력층을 만들려고 합니다. 이 신경망이 이진 분류 모델이라면 activation 매개변수에 어떤 활성화 함수를 지정해야 하나요?
- 정답: 2번 / sigmoid
- 케라스 모델에서 손실 함수와 측정 지표 등을 지정하는 메서드는 무엇인가요?
- 정답: 4번 / compile()
- 정수 레이블을 타깃으로 가지는 다중 분류일 때 케라스 모델의 compile() 메서드에 지정할 손실 함수로 적절한 것은 무엇인가요?
- 정답: 1번 / ‘sparse_categorical_crossentropy’
07-2 심층 신경망 ▶ 인공 신경망에 층을 추가하여 심층 신경망 만들어 보기
학습 목표
- 인공 신경망에 층을 여러 개 추가하여 패션 MNIST 데이터셋을 분류하면서 케라스로 심층 신경망을 만드는 방법을 자세히 배웁니다.
2개의 층
- 은닉층
- 입력층과 출력층 사이에 있는 모든 층
- 활성화 함수의 제한 X
- 뉴런 개수를 정하는 데는 특별한 기준 X
- 적어도 출력층의 뉴런보다는 많게 만들어야함.
- 출력층
- 활성화 함수 제한 有
- 분류 > for 클래스에 대한 확률 출력
- 이진 분류: sigmoid
- 다중 분류: softmax
- 회귀
- 활성화 함수 사용 X
- 출력층의 선형 방정식의 계산을 그대로 출력
- 분류 > for 클래스에 대한 확률 출력
- 활성화 함수 제한 有
심층 신경망 만들기
- 출력 크기: (None, 100)
- 첫 번째 차원: 샘플의 개수
- 샘플 개수 정의 하지 않음 → None
- 어떤 배치 크기에도 유연하게 대응
- 변경: batch_size
- 첫 번째 차원: 샘플의 개수
층을 추가하는 다른 방법
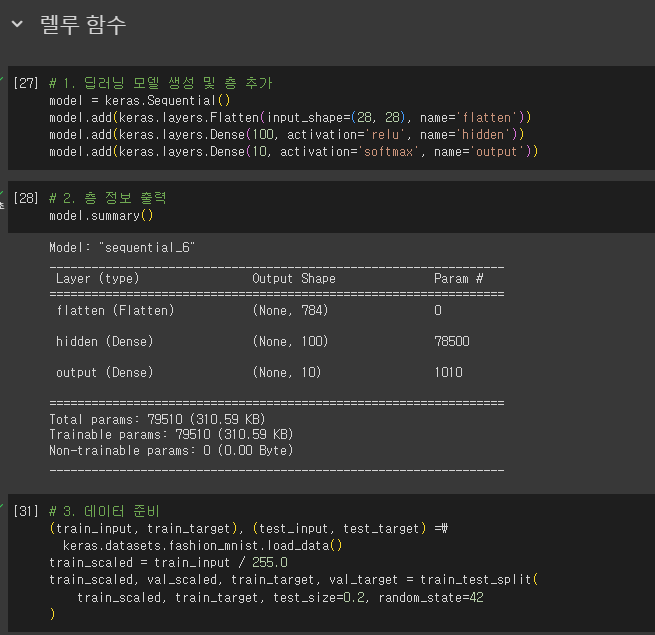
- dense1, desnse2로 만들지 않고, keras.Sequential() 함수 자체에 작성
렐루 활성화 함수
- 시그모이드 함수의 단점
- 함수의 오른쪽과 왼쪽 끝으로 갈수록 그래프가 누워있기 때문에 올바른 출력을 만드는데 신속하게 대응 불가
- 특히 층이 많은 심층 신경망일수록 그 효과가 누적 → 학습을 어렵게 만듬
- 렐루(ReLU) 함수, max(0, z)
- 시그모이드 함수의 단점 보완
- 입력이 양수일 경우 마치 활성화 함수가 없는 것처럼 입력 통과
- 음수일 경우에는 0
- 이미지 처리에 좋은 성능
- Flatten 층
- reshape() 대신 1차원으로 펼치는데 사용
- 배치 차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할
- 입력층 바로 뒤에 추가
- 입력에 곱해지는 가중치나 절편 X → 인공 신경망의 성능을 위해 기여하는 바 없음
- 케라스 API는 입력 데이터에 대한 전처리 과정을 될 수 있으면 모델에 포함함.
옵티마이저
- 하이퍼파라미터: 모델이 학습하지 않아 사람이 지정해주어야 하는 파라미터
- 은닉층의 개수
- 뉴런 개수
- 활성화 함수
- 층의 종류
- 배치 사이즈 매개변수
- default: 미니배치 경사하강법(케라스) → 미니배치 32개
- 에포크 매개변수 등
- 케라스에서 제공하는 다양한 종류의 경사 하강법 알고리즘
- default: RMSprop
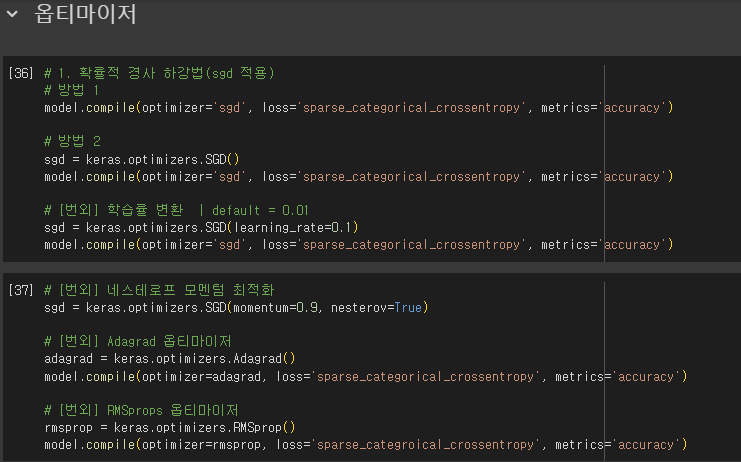
- 확률적 경사 하강법: sgd
- 1개의 샘플을 뽑아서 훈련 X
- 기본적으로 미니배치 사용
- 모멘텀 최적화(momentum optimizatio)
- 기본 경사 하강법 옵티마이저는 모두 SGD 클래스에서 제공
- SGD 클래스의 momentum 매개변수의 기본값은 0
- 이를 0보다 큰 값으로 지정하면 마치 이전의 그레디언트를 가속도처럼 사용하는 모멘텀 최적화 사용
- 보통 momentum 매개변수는 0.9이상 지정
- 네스테로프 모멘텀 최적화(nesterov momentum optimization) = 네스테로프 가속 경사
- SGD 클래스의 nesterov 매개변수를 기본값 False에서 True로 바꾼 경우 사용
- 모멘텀 최적화를 2번 반복하여 구현
- 기본 확률적 경사 하강법보다 더 나은 성능 제공
- 적응적 학습률(adaptive learning rate)
- 모델이 최적점에 가까이 갈수록 학습률 낮춤
- 이렇게 하면 안정적으로 최적점에 수렴할 가능성 높음
- 대표적인 옵티마이저
- Adagrad, RMSprop(default)
- Adam: 모멘텀 최적화와 RMSprop의 장점을 접목한 것
핵심 패키지와 함수
- TensorFlow
- add(): 케라스 모델에 층을 추가하는 메서드
- summary(): 케라스 모델의 정보를 출력하는 메서드
- SGD: 기본 경사 하강법 옵티마이저 클래스
- learning_rate 매개변수: 학습률 지정
- default: 0.01
- momentum 매개변수
- 0이상의 값을 지정하면 모멘텀 최적화 수행
- neserov 매개변수
- True로 설정하면 네스테로프 모멘텀 최적화 수행
- learning_rate 매개변수: 학습률 지정
- Adagrad: Adagrad 옵티마이저 클래스
- learning_rate 매개변수: 학습률 지정
- default: 0.001
- 그레디언트 제곱을 누적하여 학습률을 나눔
- initial_accumulator_value 매개변수: 누적 초깃값 지정 가능
- default: 0.1
- initial_accumulator_value 매개변수: 누적 초깃값 지정 가능
- learning_rate 매개변수: 학습률 지정
- RMSprop: RMSprop 옵티마이저 클래스
- learning_rate 매개변수: 학습률 지정
- default: 0.001
- Adagrad처럼 그레디언트 제곱으로 학습률을 나누지만, 최근의 그레디언트를 사용하기 위해 지수 감소 사용
- rho 매개변수: 감소 비율 지정
- default: 0.9
- rho 매개변수: 감소 비율 지정
- learning_rate 매개변수: 학습률 지정
- Adam: Adam 옵티마이저 클래스
- learning_rate 매개변수: 학습률 지정
- default: 0.001
- beta_1 매개변수: 모멘텀 최적화에 있는 그레디언트의 지수 감소 평균 조절용
- default: 0.9
- beta_2 매개변수: RMSprop에 있는 그레디언트 제곱의 지수 감소 평균 조절용
- default: 0.999
- learning_rate 매개변수: 학습률 지정
확인 문제
- 다음 중 모델의 add() 메서드 사용법이 올바른 것은 어떤 것인가요?
- 정답: 2번 / model.add(keras.layers.Dense(10, activation=’relu’)
- 크기가 300 x 300인 입력을 케라스 층으로 펼치려고 합니다. 다음 중 어떤 층을 사용해야 하나요?
- 정답: 2번 / Flatten
- 해설: Flatten 클래스는 배치 차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할만 함.
- (참고. p378) 💡 선택미션
- 다음 중에서 이미지 분류를 위한 심층 신경망에 널리 사용되는 케라스의 활성화 함수는 무엇인가요?
- 정답: 3번 / relu
- 다음 중 적응적 학습률을 사용하지 않는 옵티마이저는 무엇인가요?
- 정답: 1번 / SGD
07-3 신경망 모델 훈련 ▶ 인경 신경망 모델 훈련의 모범 사례 학습하기
학습 목표
- 인공 신경망 모델을 훈련하는 모범 사례와 필요한 도구들을 살펴보겠습니다. 이런 도구들을 다뤄 보면서 텐서플로와 케라스 API에 더 익숙해 질 것입니다.
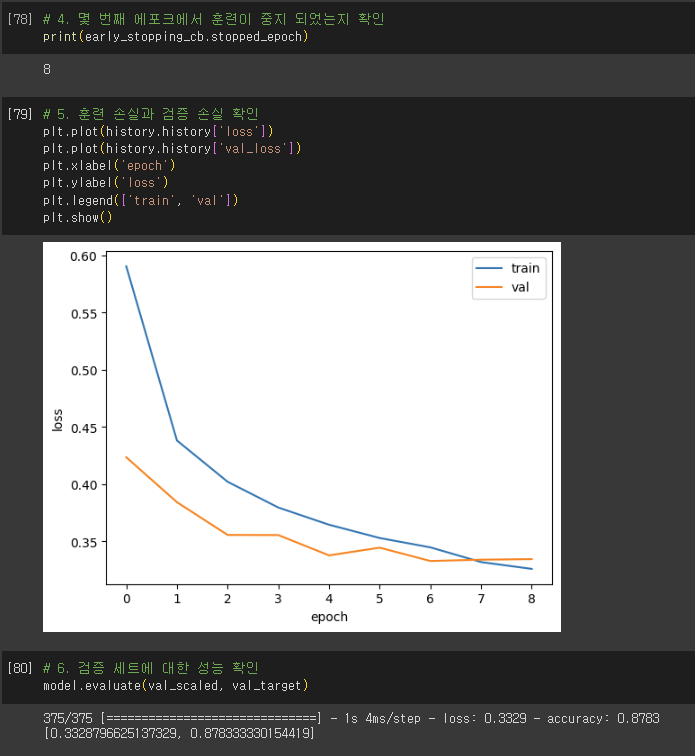
손실 곡선
- History 클래스 객체
- fit() 메서드가 반환하는 값
- 훈련 과정에서 계산한 지표, 즉 손실과 정확도 값이 저장됨.
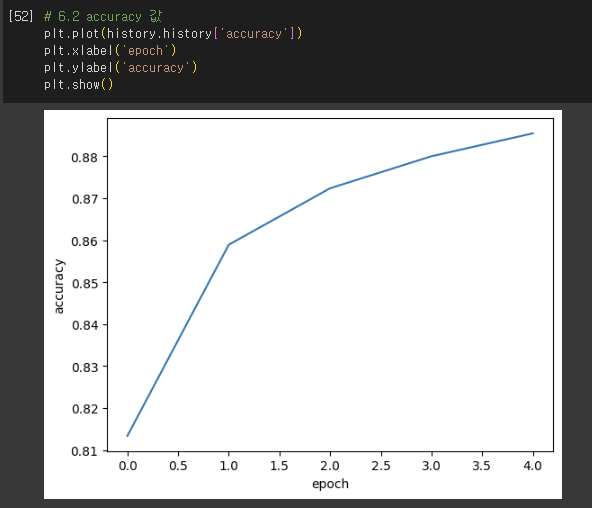
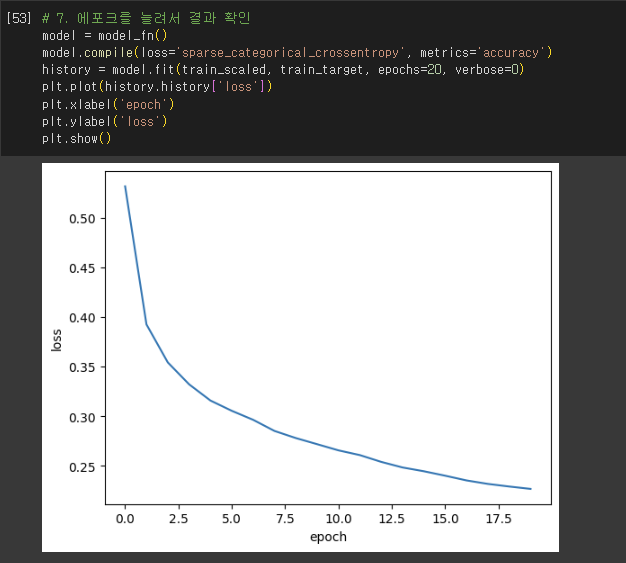
검증 손실
- 인공 신경망은 모두 일종의 경사 하강법 사용
- 에포크에 따른 과대적합/과소적합 파악
- 훈련 세트에 대한 점수 + 검증 세트에 대한 점수도 필요
- 손실을 사용하여 과대/과소적합 다루기
- 인공 신경망 모델이 최적화하는 대상: 정확도가 아니라 손실 함수!
- 손실 감소에 비례하여 정확도가 높아지지 않은 경우 有
- So, 모델이 잘 훈련되었는지 판단은 정확도보다는 손실 함수의 값 확인하는 것이 더 낫다.
- 에포크마다 검증 손실 계산
- 케라스 모델의 fit() 메서드에 검증 데이터 전달
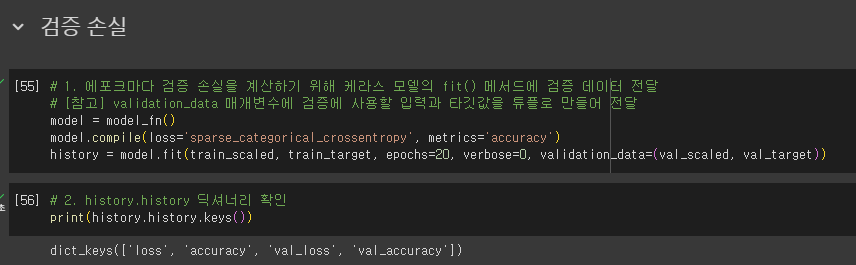
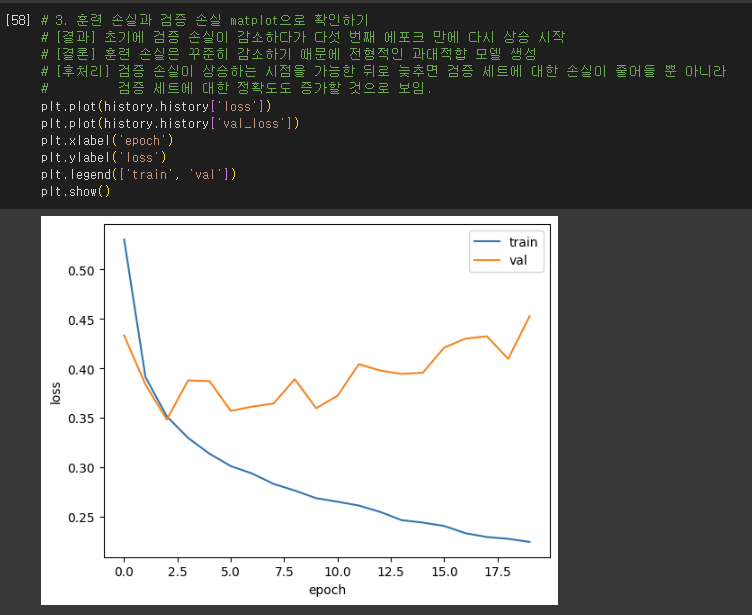
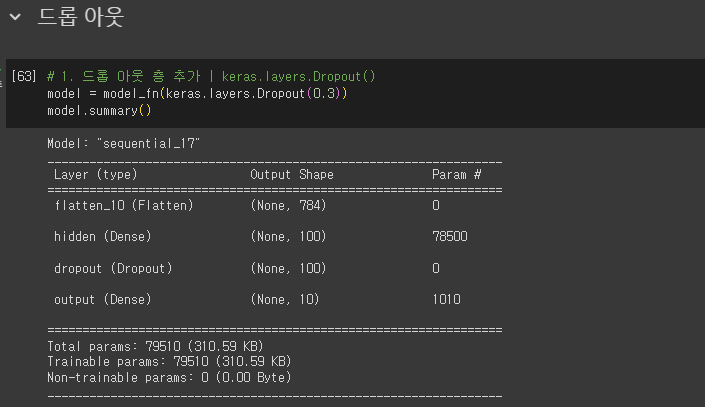
드롭아웃
- 제프리 힌턴이 소개
- 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서(즉 뉴런의 출력을 0으로 만들어) 과대적합 방지 like 앙상블 학습
- 이전 층의 일부 뉴런이 랜덤하게 꺼지면 특정 뉴런에 과대하게 의존하는 것 줄일 수 있음
- 모든 입력에 대해 주의를 기울여야 함.
- 일부 뉴런의 출력이 없을 수 있다는 것을 감안 → 이 신경망은 더 안정적인 예측 만들 수 있음.
- 앙상블 학습
- 더 좋은 예측 결과를 만들기 위해 여러 개의 모델을 훈련하는 머신러닝 알고리즘
- 과대적합 방지
- 입력과 출력 크기는 동일함.
- 단, 훈련이 끝난 뒤에 평가나 예측을 수행할 때는 드롭아웃 적용하면 안됨.
- 텐서플로와 케라스는 모델을 평가와 예측에 사용할 땐느 자동으로 드롭아웃 적용하지 않음.
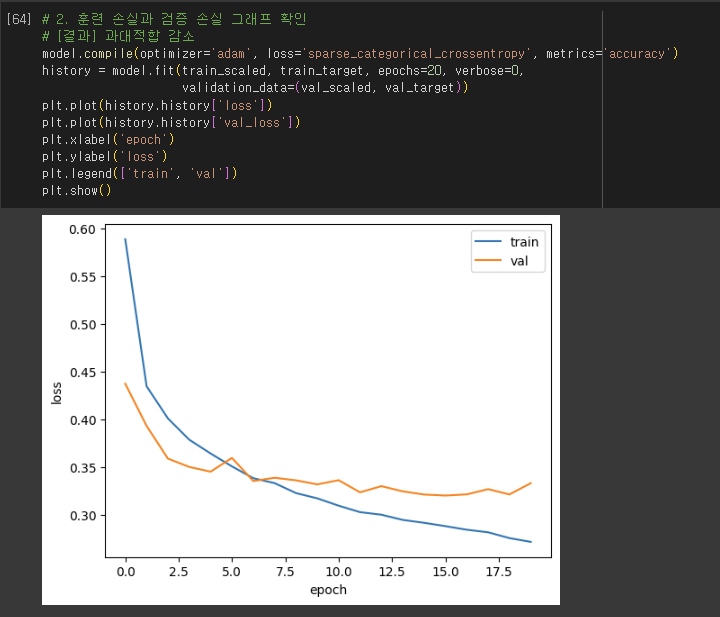
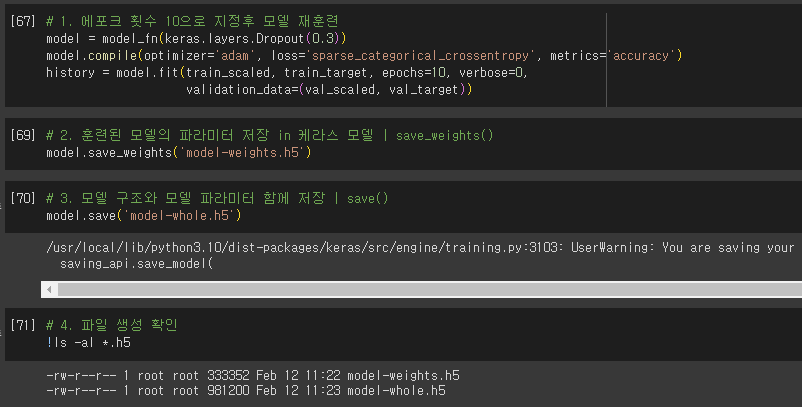
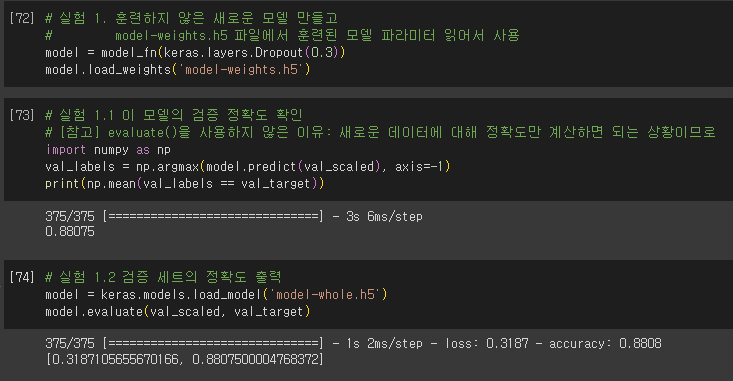
모델 저장과 복원
- model.save_weights(’파일명.확장자’)
- 확장자: h5(HDF5 포맷)
- 훈련된 모델의 파라미터 저장
- model.save(’파일명.확장자’)
- 모델 구조와 모델 파라미터 함께 저장
- model.load_weights(’파일명.확장자’)
- 사용 조건: 저장했던 모델과 정확한 구조를 가져야 함.
- model.load_model(’파일명.확장자’)
- 모델 구조와 파라미터, 옵티마이저 상태까지 모두 복원
- evaluate() 사용 가능
- 모델 구조와 파라미터, 옵티마이저 상태까지 모두 복원
콜백
- 모델을 두 번식 훈련하지 않고 한 번에 끝내는 방법
- 훈련 과정 중간에 어떤 작업을 수행할 수 있게 하는 객체
- keras.callbacks
- fit() 메서드
- callbacks 매개변수에 리스트로 전달
- ModelCheckpoint 콜백: 기본적으로 에포크마다 모델 저장
- save_best_only=True
- 가장 낮은 검증 점수를 만드는 모델 저장 가능
- save_best_only=True
- ModelCheckpoint 콜백: 기본적으로 에포크마다 모델 저장
- callbacks 매개변수에 리스트로 전달
- 조기 종료(early stopping)
- 과대적합이 커지기 전에 훈련을 미리 중지하는 것
- 계산 비용과 시간 절약 가능
- keras.callbacks.EarlyStopping()
- patience 매개변수: 검증 점수가 향상되지 않더라도 참을 에포크 횟수 지정
- restore_best_weights 매개변수
- True: 가장 낮은 검증 손실을 낸 모델 파라미터로 되돌림.
- 과대적합이 커지기 전에 훈련을 미리 중지하는 것

핵심 패키지와 함수
- TensorFlow
- Dropout: 드롭아웃 층
- 첫 번째 매개변수: 드롭아웃 할 비율(r) 지정
- 드롭아웃 하지 않는 뉴런의 출력은 1/(1-r)만큼 증가시켜 출력의 총합이 같도록 만듦.
- 모델 저장 및 읽기
- 방법 1.
- save_weight(): 모든 층의 가중치와 절편을 파일에 저장
- 첫 번째 매개변수: 저장할 파일을 지정
- save_format 매개변수: 저장할 파일 포맷 지정
- 기본적으로 텐서플로의 Checkpoint 포맷 사용
- h5 or 파일의 확장자 ‘.h5’ ⇒ HDF5 포맷으로 저장
- 기본적으로 텐서플로의 Checkpoint 포맷 사용
- load_weight(): 모든 층의 가중치와 절편을 파일에 읽음.
- 첫 번째 매개변수: 읽을 파일 지정
- save_weight(): 모든 층의 가중치와 절편을 파일에 저장
- 방법 2.
- save(): 모델 구조와 모든 가중치와 절편을 파일에 저장
- 첫 번째 매개변수: 저장할 파일 지정
- save_format 매개변수: 저장할 파일 포맷 지정
- 기본적으로 텐서플로의 Checkpoint 포맷 사용
- h5 or 파일의 확장자 ‘.h5’ ⇒ HDF5 포맷으로 저장
- 기본적으로 텐서플로의 Checkpoint 포맷 사용
- load_model(): 모델 구조와 모든 가중치 절편 파일을 읽음.
- 첫 번째 매개변수: 읽을 파일 지정
- save(): 모델 구조와 모든 가중치와 절편을 파일에 저장
- 방법 1.
- ModelCheckpoint: 케라스 모델과 가중치를 일정 간격으로 저장
- 첫 번째 매개변수: 저장할 파일 지정
- monitor 매개변수: 모니터링할 지표 지정
- default: ‘val_loss’ ⇒ 검증 손실 관찰
- save_wieghts_only 매개변수
- default: False (전체 모델 저장)
- True: 모델의 가중치와 절편만 저장
- default: False (전체 모델 저장)
- save_best_only 매개변수
- True: 가장 낮은 검증 점수를 만드는 모델 저장
- EarlyStopping: 관심 지표가 더이상 향상하지 않으면 훈련 중지
- monitor 매개변수: 모니터링할 지표 지정
- default: ‘val_loss’ ⇒ 검증 손실 관찰
- patience 매개변수: 모델이 더 이상 향상되지 않고 지속할 수 있는 최대 에포크 횟수 지정
- restore_best_weights 매개변수: 최상의 모델 가중치를 복원할 지정
- default: False
- monitor 매개변수: 모니터링할 지표 지정
- Dropout: 드롭아웃 층
- Numpy
- argmax: 배열에서 축을 따라 최댓값의 인덱스 반환
- axis 매개변수: 어떤 축을 따라 최댓값을 찾을 지 지정
- default: None(전체 배열에서 최대값 찾음)
- axis 매개변수: 어떤 축을 따라 최댓값을 찾을 지 지정
- argmax: 배열에서 축을 따라 최댓값의 인덱스 반환
확인 문제
- 케라스 모델의 fit() 메서드에 검증 세트를 올바르게 전달하는 코드는 무엇인가요?
- 정답: 4번 / model.fit(…, validation_data = (val_input, val_target))
- 이전 층의 뉴런 출력 중 70%만 사용하기 위해 드롭아웃 층을 추가하려고 합니다. 다음 중 옳게 설정한 것은 무엇인가요?
- 정답: 2번 / Dropout(0.3)
- 케라스 모델의 가중치만 저장하는 메서드는 무엇인가요?
- 정답: 3번 / save_weights()
- 케라스의 조기 종료 콜백을 사용하려고 합니다. 3번의 에포크 동안 손실이 감소되지 않으면 종료하고 최상의 모델 가중치를 복원하도록 올바르게 설정한 것은 무엇인가요?
- 정답: 2번 / EarlyStopping(monitor=’val_loss’, patience=3, restore_best_weights=True)
혼공학습단 6주차 활동 소감
명절을 보내고, 부랴부랴 6주차 학습을 진행했습니다. 혼공학습단은 6주면 끝이지만, 남은 Chapter 8과 9도 마무리하고 싶은 마음에 차주에도 학습은 이어가보려 합니다. 인공지능 처음에는 정말 어렵게 느껴졌지만, 주차를 거듭할수록 어려움이 반감되었습니다. 특히, 일일이 손코딩하며 학습했는데 저자님의 말씀처럼 '이게 키포인트'였다고 생각합니다. 단순히 따라치는 것일지라도 코드를 직접 쳐보면서 하나하나 제것이 되는 느낌을 받았습니다. 이 책을 끝내고 나면, 다음 책은 어떤 책을 보면 좋을 지도 내심 찾아보게 됩니다. 금주도 정말 재밌는 공부가 되었습니다. 감사합니다. (더 자세한 내용은 회고글로 찾아뵐게요.)
손코딩 자료
1. Chapter 07. 딥러닝을 시작합니다.(Github 링크)
'코딩 | 개념 정리 > Machine Learning & Deep Learning' 카테고리의 다른 글
| [혼공머신] 혼공학습단 11기_학습 회고 (0) | 2024.02.18 |
|---|---|
| [혼공머신] 번외주차_이미지를 위한 인공 신경망 (0) | 2024.02.17 |
| [혼공머신] 5주차_비지도 학습 (0) | 2024.02.03 |
| [혼공머신] 4주차_트리 알고리즘 (0) | 2024.01.27 |
| [혼공머신] 3주차_다양한 분류 알고리즘 (0) | 2024.01.20 |
Chapter 07 딥러닝을 시작합니다 ▶ 패션 럭키백을 판매합니다!
07-1 인공 신경망 ▶ 텐서플로로 간단한 인공 신경망 모델 만들기
학습 목표
- 딥러닝과 인공 신경망 알고리즘을 이해하고 텐서플로를 사용해 간단한 인공 신경망 모델을 만들어봅시다.
패션 MNIST
- MNIST
- 머신러닝: 붓꽃 데이터셋
- 딥러닝: MNIST 데이터셋
- 손으로쓴 0~9까지의 숫자로 이루어짐
- 패션 MNIST
- MNIST와 크기, 개수가 동일하지만 숫자 대신 패션 아이템으로 이루어진 데이터
- 각 픽셀은 0~255 사이의 정숫값을 가짐
- 이런 이미지의 경우 보통 255로 나누어 0~1 사이의 값으로 정규화
- 이는 표준화는 아니지만 양수 값으로 이루어진 이미지를 전처리할 때 널리 사용하는 방법
로지스틱 회귀로 패션 아이템 분류하기
인공 신경망
- ANN(Artificial Neural Network)
- 가장 기본적인 인공 신경망 = 확률적 경사 하강법을 사용하는 로지스틱 회귀
- 입력층(input layer)
- 출력층(output layer)
- 뉴런(neuron) = 유닛(unit)
- 인공 신경망에서 z값을 계산하는 단위
- 인공 신경망의 등장
- 1943년, 매컬러-피츠 뉴런
- 기존의 머신러닝 알고리즘이 잘 해결하지 못했던 문제에서 높은 성능을 발휘하는 새로운 종류의 머신러닝 알고리즘
- 딥러닝 = 인공 신경망
- 딥러닝(DNN, Deep Neural Network)
- 심층 신경망: 여러 개의 층을 가진 인공 신경망
- 텐서플로
- 2015년 11월, 구글이 오픈소스로 공개한 딥러닝 라이브러리
- 저수준 API vs. 고수준 API
- 케라스(Keras): 텐서플로의 고수준 API
- 직접 GPU 연산 수행 X
- 대신 GPU 연산을 수행하는 다른 라이브러리 백엔드(backend) 사용
- 케라스의 백엔드
- ex. 텐서플로, 씨아노, CNTK 등 ⇒ 멀티-백엔드 케라스
- 멀티-백엔드 케라스는 2.3.1 버전 이후로 더이상 개발 X
- So, 텐서플로 = 케라스
- 케라스(Keras): 텐서플로의 고수준 API
- 딥러닝 라이브러리와 머신러닝 라이브러리의 차이점
- 그래픽 처리 장치인 GPU를 사용하여 인공 신경망 훈련
- GPU: 벡터와 행렬 연산에 매우 최적화 → 곱셈과 덧셈이 많이 수행되는 인공 신경망에 큰 도움.
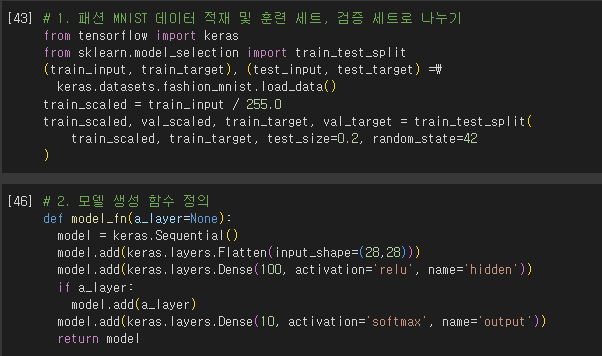
인공 신경망으로 모델 만들기
- 로지스틱 회귀에서는 교차 검증 → 모델 평가
- 인공 신경망에서는 검증 세트를 별도로 덜어 내어 → 모델 평가
- 이유 1. 딥러닝 분야의 데이터셋은 충분히 크기 때문에, 검증 점수가 안정적
- 이유 2. 교차 검증을 수행하기에는 훈련 시간이 너무 오래 걸림.
- 케라스의 레이어(keras.layers) 패키지 안에 층
- 밀집층(dense layer)
- 빼곡하게 연결되어 있으므로(ex. 784 x 10 = 7,840)
- 완전 연결층(fully connected layer)
- 양쪽의 뉴런이 모두 연결하고 있으므로
- 밀집층(dense layer)
- 입력층과 출력층 사이에서 연결선만 표시, 가중치 표시 X
- 절편의 경우는 아예 선도 안그리는 경우 多
- 하지만, 절편이 뉴런마다 더해진다는 사실!
- 활성화 함수(activation function) → a
- 소프트맥스와 같이 뉴런의 선형 방정식 계산 결과에 적용되는 함수
인공 신경망으로 패션 아이템 분류하기
- 케라스 모델 훈련 전 설정 단계
- 손실 함수
- 이진 분류: loss = ‘binary_crossentropy’
- 다중 분류: loss = ‘categorical_crossentropy’
- 결국 신경망은 티셔츠 샘플에서 손실을 낮추려면 첫 번째 뉴런의 활성화 출력 a1의 값을 가능한 1에 가깝게 만들어야함.
- 크로스 엔트로피 손실 함수가 신경망에서 원하는 바
- 원-핫 인코딩(one-hot encoding)
- 타깃값을 해당 클래스만 1(hot)이고 나머지는 모두 0인 배열로 만드는 것
- 손실 함수
- sprase_categorical_crossentropy
- 정수로된 타깃값을 사용해 크로스 엔트로피 손실 계산
- sprase(희소)
- 케라스
- 모델이 훈련할 때 기본으로 에포크마다 손실 값 출력
- 손실값과 함께 정확도를 함께 확인하기 위해
- metrics=’accuracy’로 지정
핵심 패키지와 함수
- Tensorflow
- Dense: 신경망에서 가장 기본 층민 밀집층을 만드는 클래스
- 첫 번째 매개변수: 뉴런의 개수 지정
- activation 매개변수: 매개변수에 사용할 활성화 함수 지정
- 이진 분류: sigmoid
- 다중 분류: softmax
- default: 사용 x
- input_shape 매개변수: 입력의 크기 지정
- Sequential: 케라스에서 신경망 모델을 만드는 클래스
- 이 클래스의 객체를 생성할 때, 신경망 모델에 추가할 층 지정 가능
- 추가할 층이 1개 이상일 경우, 파이썬 리스트로 전달
- compile(): 모델 객체를 만든 후 훈련하기 전에 사용할 손실 함수와 측정 지표 등을 지정하는 메서드
- loss 매개변수: 손실 함수 지정
- 이진 분류: binary_crossentropy
- 다중 분류: categorical_crossentropy
- 클래스 레이블이 정수일 경우: sparse_categorical_crossentropy
- 회구 모델일 경우: mean_square_error
- metrics 매개변수: 훈련 과정에서 측정하고 싶은 지표 지정
- 측정 지표가 1개 이상일 경울 ㅣ스트로 전달
- loss 매개변수: 손실 함수 지정
- fit(): 모델 훈련 메서드
- 첫 번째 매개변수: 입력 데이터
- 두 번째 매개변수: 타깃 데이터
- epochs 매개변수: 전체 데이터에 대해 반복할 에포크 횟수 지정
- evaluate(): 모델 성능 평가 메서드
- 첫 번째 매개변수: 입력 데이터
- 두 번째 매개변수: 타깃 데이터
- compie() 메서드에서 loss 매개변수에 지정한 손실 함수의 값과 metrics 매개변수에서 지정한 측정 지표 출력
- Dense: 신경망에서 가장 기본 층민 밀집층을 만드는 클래스
확인 문제
- 어떤 인공 신경망의 입력 특성이 100개이고 밀집층에 있는 뉴런 개수가 10개일 때 필요한 모델 파라미터의 개수는 몇 개인가요?
- 정답: 1번 / 1,000개 = 100 x 10 💡 기본 미션
- 케라스의 Dense 클래스를 사용해 신경망의 출력층을 만들려고 합니다. 이 신경망이 이진 분류 모델이라면 activation 매개변수에 어떤 활성화 함수를 지정해야 하나요?
- 정답: 2번 / sigmoid
- 케라스 모델에서 손실 함수와 측정 지표 등을 지정하는 메서드는 무엇인가요?
- 정답: 4번 / compile()
- 정수 레이블을 타깃으로 가지는 다중 분류일 때 케라스 모델의 compile() 메서드에 지정할 손실 함수로 적절한 것은 무엇인가요?
- 정답: 1번 / ‘sparse_categorical_crossentropy’
07-2 심층 신경망 ▶ 인공 신경망에 층을 추가하여 심층 신경망 만들어 보기
학습 목표
- 인공 신경망에 층을 여러 개 추가하여 패션 MNIST 데이터셋을 분류하면서 케라스로 심층 신경망을 만드는 방법을 자세히 배웁니다.
2개의 층
- 은닉층
- 입력층과 출력층 사이에 있는 모든 층
- 활성화 함수의 제한 X
- 뉴런 개수를 정하는 데는 특별한 기준 X
- 적어도 출력층의 뉴런보다는 많게 만들어야함.
- 출력층
- 활성화 함수 제한 有
- 분류 > for 클래스에 대한 확률 출력
- 이진 분류: sigmoid
- 다중 분류: softmax
- 회귀
- 활성화 함수 사용 X
- 출력층의 선형 방정식의 계산을 그대로 출력
- 분류 > for 클래스에 대한 확률 출력
- 활성화 함수 제한 有
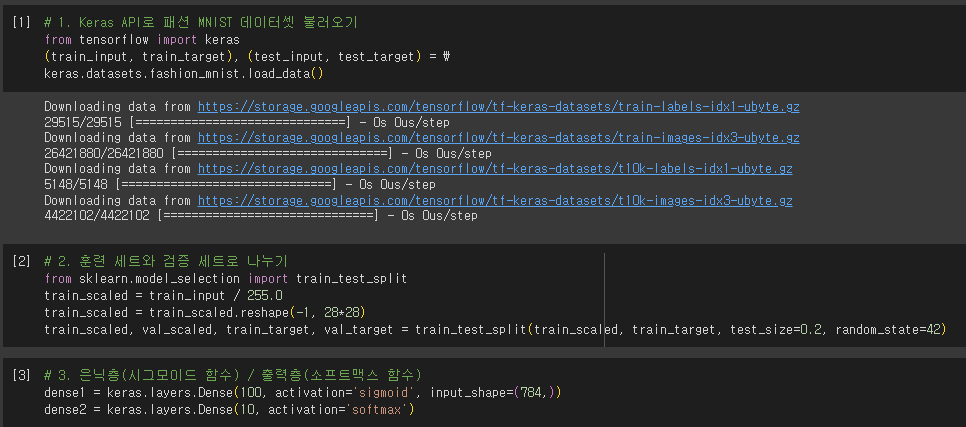
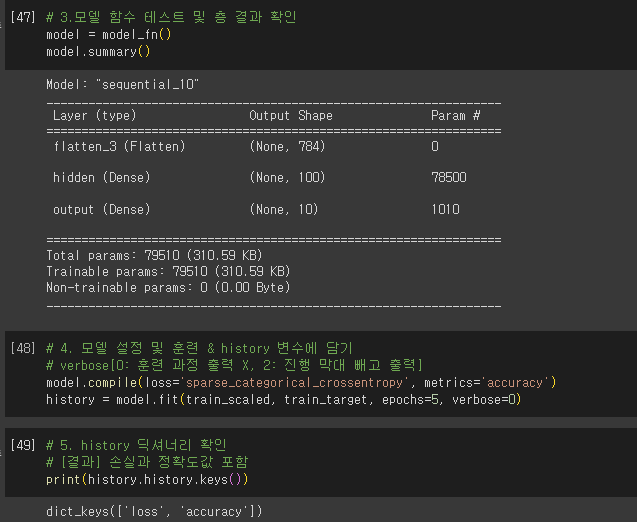
심층 신경망 만들기
- 출력 크기: (None, 100)
- 첫 번째 차원: 샘플의 개수
- 샘플 개수 정의 하지 않음 → None
- 어떤 배치 크기에도 유연하게 대응
- 변경: batch_size
- 첫 번째 차원: 샘플의 개수
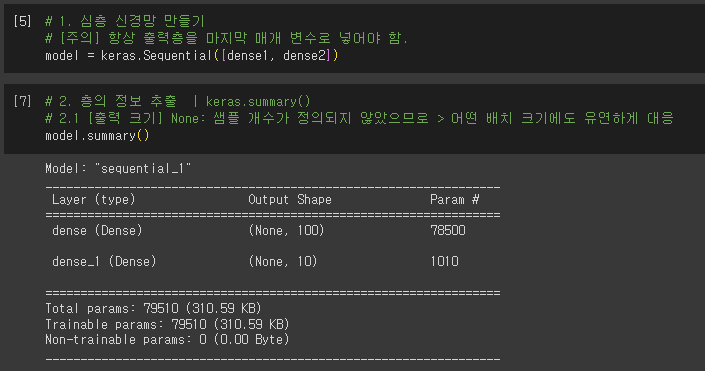
층을 추가하는 다른 방법
- dense1, desnse2로 만들지 않고, keras.Sequential() 함수 자체에 작성
렐루 활성화 함수
- 시그모이드 함수의 단점
- 함수의 오른쪽과 왼쪽 끝으로 갈수록 그래프가 누워있기 때문에 올바른 출력을 만드는데 신속하게 대응 불가
- 특히 층이 많은 심층 신경망일수록 그 효과가 누적 → 학습을 어렵게 만듬
- 렐루(ReLU) 함수, max(0, z)
- 시그모이드 함수의 단점 보완
- 입력이 양수일 경우 마치 활성화 함수가 없는 것처럼 입력 통과
- 음수일 경우에는 0
- 이미지 처리에 좋은 성능
- Flatten 층
- reshape() 대신 1차원으로 펼치는데 사용
- 배치 차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할
- 입력층 바로 뒤에 추가
- 입력에 곱해지는 가중치나 절편 X → 인공 신경망의 성능을 위해 기여하는 바 없음
- 케라스 API는 입력 데이터에 대한 전처리 과정을 될 수 있으면 모델에 포함함.
옵티마이저
- 하이퍼파라미터: 모델이 학습하지 않아 사람이 지정해주어야 하는 파라미터
- 은닉층의 개수
- 뉴런 개수
- 활성화 함수
- 층의 종류
- 배치 사이즈 매개변수
- default: 미니배치 경사하강법(케라스) → 미니배치 32개
- 에포크 매개변수 등
- 케라스에서 제공하는 다양한 종류의 경사 하강법 알고리즘
- default: RMSprop
- 확률적 경사 하강법: sgd
- 1개의 샘플을 뽑아서 훈련 X
- 기본적으로 미니배치 사용
- 모멘텀 최적화(momentum optimizatio)
- 기본 경사 하강법 옵티마이저는 모두 SGD 클래스에서 제공
- SGD 클래스의 momentum 매개변수의 기본값은 0
- 이를 0보다 큰 값으로 지정하면 마치 이전의 그레디언트를 가속도처럼 사용하는 모멘텀 최적화 사용
- 보통 momentum 매개변수는 0.9이상 지정
- 네스테로프 모멘텀 최적화(nesterov momentum optimization) = 네스테로프 가속 경사
- SGD 클래스의 nesterov 매개변수를 기본값 False에서 True로 바꾼 경우 사용
- 모멘텀 최적화를 2번 반복하여 구현
- 기본 확률적 경사 하강법보다 더 나은 성능 제공
- 적응적 학습률(adaptive learning rate)
- 모델이 최적점에 가까이 갈수록 학습률 낮춤
- 이렇게 하면 안정적으로 최적점에 수렴할 가능성 높음
- 대표적인 옵티마이저
- Adagrad, RMSprop(default)
- Adam: 모멘텀 최적화와 RMSprop의 장점을 접목한 것
핵심 패키지와 함수
- TensorFlow
- add(): 케라스 모델에 층을 추가하는 메서드
- summary(): 케라스 모델의 정보를 출력하는 메서드
- SGD: 기본 경사 하강법 옵티마이저 클래스
- learning_rate 매개변수: 학습률 지정
- default: 0.01
- momentum 매개변수
- 0이상의 값을 지정하면 모멘텀 최적화 수행
- neserov 매개변수
- True로 설정하면 네스테로프 모멘텀 최적화 수행
- learning_rate 매개변수: 학습률 지정
- Adagrad: Adagrad 옵티마이저 클래스
- learning_rate 매개변수: 학습률 지정
- default: 0.001
- 그레디언트 제곱을 누적하여 학습률을 나눔
- initial_accumulator_value 매개변수: 누적 초깃값 지정 가능
- default: 0.1
- initial_accumulator_value 매개변수: 누적 초깃값 지정 가능
- learning_rate 매개변수: 학습률 지정
- RMSprop: RMSprop 옵티마이저 클래스
- learning_rate 매개변수: 학습률 지정
- default: 0.001
- Adagrad처럼 그레디언트 제곱으로 학습률을 나누지만, 최근의 그레디언트를 사용하기 위해 지수 감소 사용
- rho 매개변수: 감소 비율 지정
- default: 0.9
- rho 매개변수: 감소 비율 지정
- learning_rate 매개변수: 학습률 지정
- Adam: Adam 옵티마이저 클래스
- learning_rate 매개변수: 학습률 지정
- default: 0.001
- beta_1 매개변수: 모멘텀 최적화에 있는 그레디언트의 지수 감소 평균 조절용
- default: 0.9
- beta_2 매개변수: RMSprop에 있는 그레디언트 제곱의 지수 감소 평균 조절용
- default: 0.999
- learning_rate 매개변수: 학습률 지정
확인 문제
- 다음 중 모델의 add() 메서드 사용법이 올바른 것은 어떤 것인가요?
- 정답: 2번 / model.add(keras.layers.Dense(10, activation=’relu’)
- 크기가 300 x 300인 입력을 케라스 층으로 펼치려고 합니다. 다음 중 어떤 층을 사용해야 하나요?
- 정답: 2번 / Flatten
- 해설: Flatten 클래스는 배치 차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할만 함.
- (참고. p378) 💡 선택미션
- 다음 중에서 이미지 분류를 위한 심층 신경망에 널리 사용되는 케라스의 활성화 함수는 무엇인가요?
- 정답: 3번 / relu
- 다음 중 적응적 학습률을 사용하지 않는 옵티마이저는 무엇인가요?
- 정답: 1번 / SGD
07-3 신경망 모델 훈련 ▶ 인경 신경망 모델 훈련의 모범 사례 학습하기
학습 목표
- 인공 신경망 모델을 훈련하는 모범 사례와 필요한 도구들을 살펴보겠습니다. 이런 도구들을 다뤄 보면서 텐서플로와 케라스 API에 더 익숙해 질 것입니다.
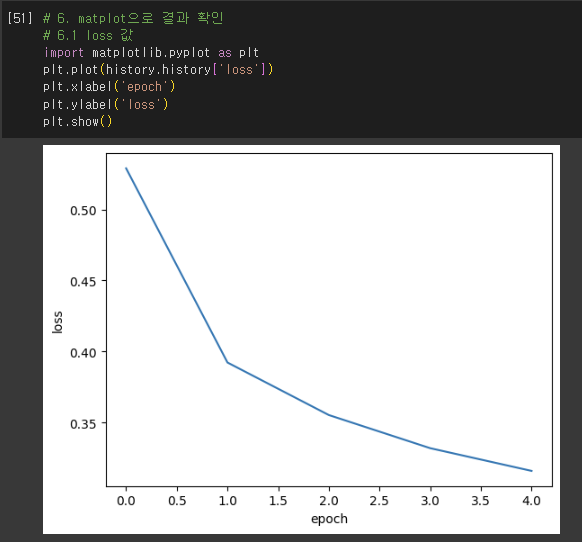
손실 곡선
- History 클래스 객체
- fit() 메서드가 반환하는 값
- 훈련 과정에서 계산한 지표, 즉 손실과 정확도 값이 저장됨.
검증 손실
- 인공 신경망은 모두 일종의 경사 하강법 사용
- 에포크에 따른 과대적합/과소적합 파악
- 훈련 세트에 대한 점수 + 검증 세트에 대한 점수도 필요
- 손실을 사용하여 과대/과소적합 다루기
- 인공 신경망 모델이 최적화하는 대상: 정확도가 아니라 손실 함수!
- 손실 감소에 비례하여 정확도가 높아지지 않은 경우 有
- So, 모델이 잘 훈련되었는지 판단은 정확도보다는 손실 함수의 값 확인하는 것이 더 낫다.
- 에포크마다 검증 손실 계산
- 케라스 모델의 fit() 메서드에 검증 데이터 전달
드롭아웃
- 제프리 힌턴이 소개
- 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서(즉 뉴런의 출력을 0으로 만들어) 과대적합 방지 like 앙상블 학습
- 이전 층의 일부 뉴런이 랜덤하게 꺼지면 특정 뉴런에 과대하게 의존하는 것 줄일 수 있음
- 모든 입력에 대해 주의를 기울여야 함.
- 일부 뉴런의 출력이 없을 수 있다는 것을 감안 → 이 신경망은 더 안정적인 예측 만들 수 있음.
- 앙상블 학습
- 더 좋은 예측 결과를 만들기 위해 여러 개의 모델을 훈련하는 머신러닝 알고리즘
- 과대적합 방지
- 입력과 출력 크기는 동일함.
- 단, 훈련이 끝난 뒤에 평가나 예측을 수행할 때는 드롭아웃 적용하면 안됨.
- 텐서플로와 케라스는 모델을 평가와 예측에 사용할 땐느 자동으로 드롭아웃 적용하지 않음.
모델 저장과 복원
- model.save_weights(’파일명.확장자’)
- 확장자: h5(HDF5 포맷)
- 훈련된 모델의 파라미터 저장
- model.save(’파일명.확장자’)
- 모델 구조와 모델 파라미터 함께 저장
- model.load_weights(’파일명.확장자’)
- 사용 조건: 저장했던 모델과 정확한 구조를 가져야 함.
- model.load_model(’파일명.확장자’)
- 모델 구조와 파라미터, 옵티마이저 상태까지 모두 복원
- evaluate() 사용 가능
- 모델 구조와 파라미터, 옵티마이저 상태까지 모두 복원
콜백
- 모델을 두 번식 훈련하지 않고 한 번에 끝내는 방법
- 훈련 과정 중간에 어떤 작업을 수행할 수 있게 하는 객체
- keras.callbacks
- fit() 메서드
- callbacks 매개변수에 리스트로 전달
- ModelCheckpoint 콜백: 기본적으로 에포크마다 모델 저장
- save_best_only=True
- 가장 낮은 검증 점수를 만드는 모델 저장 가능
- save_best_only=True
- ModelCheckpoint 콜백: 기본적으로 에포크마다 모델 저장
- callbacks 매개변수에 리스트로 전달
- 조기 종료(early stopping)
- 과대적합이 커지기 전에 훈련을 미리 중지하는 것
- 계산 비용과 시간 절약 가능
- keras.callbacks.EarlyStopping()
- patience 매개변수: 검증 점수가 향상되지 않더라도 참을 에포크 횟수 지정
- restore_best_weights 매개변수
- True: 가장 낮은 검증 손실을 낸 모델 파라미터로 되돌림.
- 과대적합이 커지기 전에 훈련을 미리 중지하는 것
핵심 패키지와 함수
- TensorFlow
- Dropout: 드롭아웃 층
- 첫 번째 매개변수: 드롭아웃 할 비율(r) 지정
- 드롭아웃 하지 않는 뉴런의 출력은 1/(1-r)만큼 증가시켜 출력의 총합이 같도록 만듦.
- 모델 저장 및 읽기
- 방법 1.
- save_weight(): 모든 층의 가중치와 절편을 파일에 저장
- 첫 번째 매개변수: 저장할 파일을 지정
- save_format 매개변수: 저장할 파일 포맷 지정
- 기본적으로 텐서플로의 Checkpoint 포맷 사용
- h5 or 파일의 확장자 ‘.h5’ ⇒ HDF5 포맷으로 저장
- 기본적으로 텐서플로의 Checkpoint 포맷 사용
- load_weight(): 모든 층의 가중치와 절편을 파일에 읽음.
- 첫 번째 매개변수: 읽을 파일 지정
- save_weight(): 모든 층의 가중치와 절편을 파일에 저장
- 방법 2.
- save(): 모델 구조와 모든 가중치와 절편을 파일에 저장
- 첫 번째 매개변수: 저장할 파일 지정
- save_format 매개변수: 저장할 파일 포맷 지정
- 기본적으로 텐서플로의 Checkpoint 포맷 사용
- h5 or 파일의 확장자 ‘.h5’ ⇒ HDF5 포맷으로 저장
- 기본적으로 텐서플로의 Checkpoint 포맷 사용
- load_model(): 모델 구조와 모든 가중치 절편 파일을 읽음.
- 첫 번째 매개변수: 읽을 파일 지정
- save(): 모델 구조와 모든 가중치와 절편을 파일에 저장
- 방법 1.
- ModelCheckpoint: 케라스 모델과 가중치를 일정 간격으로 저장
- 첫 번째 매개변수: 저장할 파일 지정
- monitor 매개변수: 모니터링할 지표 지정
- default: ‘val_loss’ ⇒ 검증 손실 관찰
- save_wieghts_only 매개변수
- default: False (전체 모델 저장)
- True: 모델의 가중치와 절편만 저장
- default: False (전체 모델 저장)
- save_best_only 매개변수
- True: 가장 낮은 검증 점수를 만드는 모델 저장
- EarlyStopping: 관심 지표가 더이상 향상하지 않으면 훈련 중지
- monitor 매개변수: 모니터링할 지표 지정
- default: ‘val_loss’ ⇒ 검증 손실 관찰
- patience 매개변수: 모델이 더 이상 향상되지 않고 지속할 수 있는 최대 에포크 횟수 지정
- restore_best_weights 매개변수: 최상의 모델 가중치를 복원할 지정
- default: False
- monitor 매개변수: 모니터링할 지표 지정
- Dropout: 드롭아웃 층
- Numpy
- argmax: 배열에서 축을 따라 최댓값의 인덱스 반환
- axis 매개변수: 어떤 축을 따라 최댓값을 찾을 지 지정
- default: None(전체 배열에서 최대값 찾음)
- axis 매개변수: 어떤 축을 따라 최댓값을 찾을 지 지정
- argmax: 배열에서 축을 따라 최댓값의 인덱스 반환
확인 문제
- 케라스 모델의 fit() 메서드에 검증 세트를 올바르게 전달하는 코드는 무엇인가요?
- 정답: 4번 / model.fit(…, validation_data = (val_input, val_target))
- 이전 층의 뉴런 출력 중 70%만 사용하기 위해 드롭아웃 층을 추가하려고 합니다. 다음 중 옳게 설정한 것은 무엇인가요?
- 정답: 2번 / Dropout(0.3)
- 케라스 모델의 가중치만 저장하는 메서드는 무엇인가요?
- 정답: 3번 / save_weights()
- 케라스의 조기 종료 콜백을 사용하려고 합니다. 3번의 에포크 동안 손실이 감소되지 않으면 종료하고 최상의 모델 가중치를 복원하도록 올바르게 설정한 것은 무엇인가요?
- 정답: 2번 / EarlyStopping(monitor=’val_loss’, patience=3, restore_best_weights=True)
혼공학습단 6주차 활동 소감
명절을 보내고, 부랴부랴 6주차 학습을 진행했습니다. 혼공학습단은 6주면 끝이지만, 남은 Chapter 8과 9도 마무리하고 싶은 마음에 차주에도 학습은 이어가보려 합니다. 인공지능 처음에는 정말 어렵게 느껴졌지만, 주차를 거듭할수록 어려움이 반감되었습니다. 특히, 일일이 손코딩하며 학습했는데 저자님의 말씀처럼 '이게 키포인트'였다고 생각합니다. 단순히 따라치는 것일지라도 코드를 직접 쳐보면서 하나하나 제것이 되는 느낌을 받았습니다. 이 책을 끝내고 나면, 다음 책은 어떤 책을 보면 좋을 지도 내심 찾아보게 됩니다. 금주도 정말 재밌는 공부가 되었습니다. 감사합니다. (더 자세한 내용은 회고글로 찾아뵐게요.)
손코딩 자료
1. Chapter 07. 딥러닝을 시작합니다.(Github 링크)
'코딩 | 개념 정리 > Machine Learning & Deep Learning' 카테고리의 다른 글
| [혼공머신] 혼공학습단 11기_학습 회고 (0) | 2024.02.18 |
|---|---|
| [혼공머신] 번외주차_이미지를 위한 인공 신경망 (0) | 2024.02.17 |
| [혼공머신] 5주차_비지도 학습 (0) | 2024.02.03 |
| [혼공머신] 4주차_트리 알고리즘 (0) | 2024.01.27 |
| [혼공머신] 3주차_다양한 분류 알고리즘 (0) | 2024.01.20 |