

Chapter 05 트리 알고리즘 ▶ 화이트 와인을 찾아라!
05-1 결정 트리 ▶ 결정 트리 알고리즘을 사용해 새로운 분류 문제 다루기
학습 목표
- 결정 트리 알고리즘을 사용해 새로운 분류 문제를 다루어 봅니다. 결정 트리가 머신러닝 문제를 어떻게 해결하는지 이해합니다.
로지스틱 회귀로 와인 분류하기
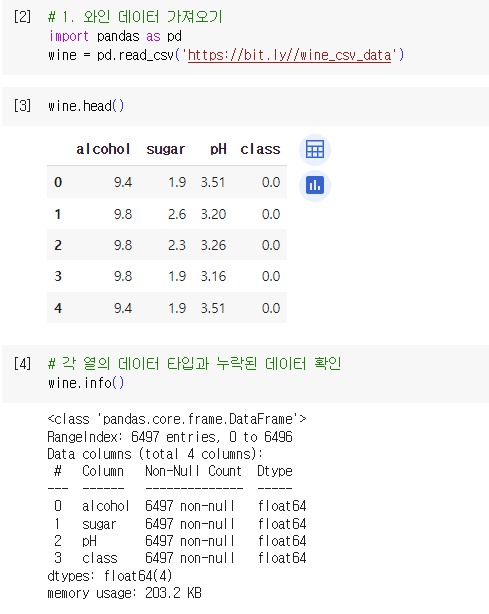
데이터프레임의 각 열의 데이터 타입과 누락된 데이터 확인
- pandas.info() 이용
누락된 값이 있는 경우
- 해당 데이터 버리기
- 평균값으로 채워 사용
- (명심) 항상 훈련 세트의 통계 값으로 테스트 세트를 변환한다
- 즉, 훈련 세트의 평균값으로 테스트 세트의 누락된 값을 채워야 함.
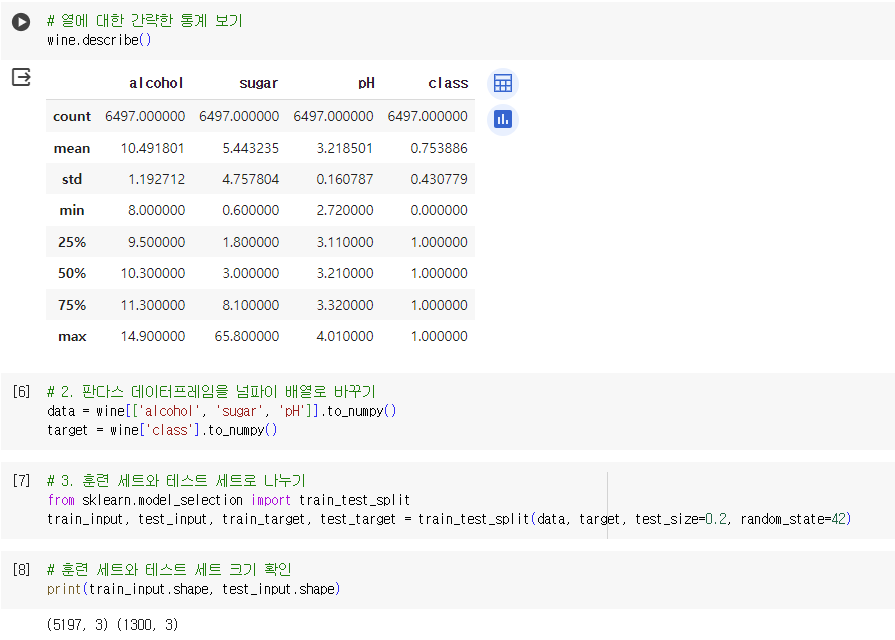
데이터프레임의 열에 대한 간략한 통계 보기
- pandas.describe() 이용
- 확인값: 평균(mean), 표준편차(std), 최소(min), 최대(max), 1분위수(25%), 2분위수/중간값(50%), 3분위수(75%)
 012
012
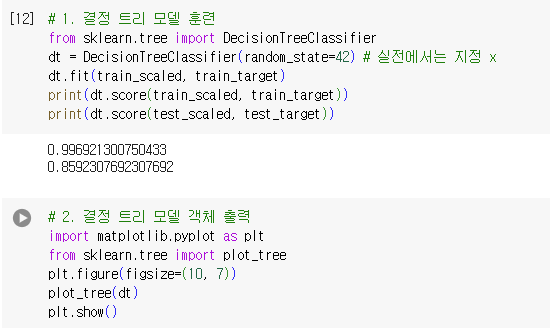
결정 트리
- 예 / 아니오에 대한 질문을 이어나가면서 정답을 찾아 학습하는 알고리즘
- 비교적 예측 과정을 이해하기 쉽고 성능이 뛰어남.
- DecisionTreeClassifier 클래스 사용
- 결정 트리 모델은 부모 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장 시킴.
불순도
- 결정 트리가 최적의 질문을 찾기 위한 기준
- at 사이킷런
- 지니 불순도
- 엔트로피 불순도
- at 사이킷런
- gini = 지니 불순도(Gini impunity)
- DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값이 ‘gini’
- 지니 불순도 = 1 - (음성 클래스 비율^2 + 양성 클래스 비율^2)
- 불순도 차이 = 부모의 불순도 - (왼쪽 노드 샘플 수 / 부모의 샘플 수) * 왼쪽 노드 불순도 - (오른쪽 노드 샘플 수 / 부모의 샘플 수) * 오른쪽 노드 불순도
- 정보 이득(information gain) = 부모와 자식 노드 사이의 불순도 차이
가지치기
- 방법: 트리의 최대 깊이 지정
- 사용 목적
- 결정 트리는 제한 없이 성장하면 훈련 세트에 과대적합되기 쉬움.
특성 중요도
- 결정 트리에 사용된 특성이 불순도를 감소하는데 기여한 정도를 나타내는 값
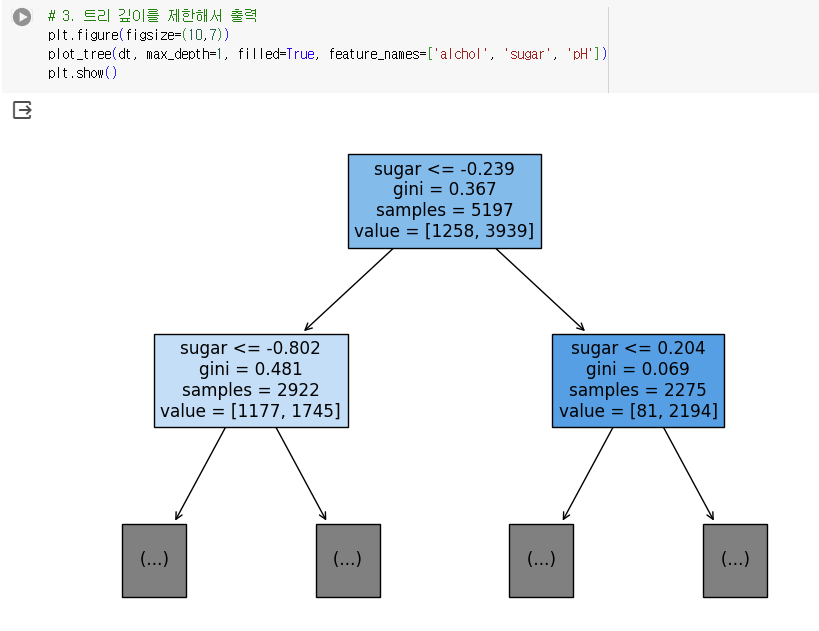
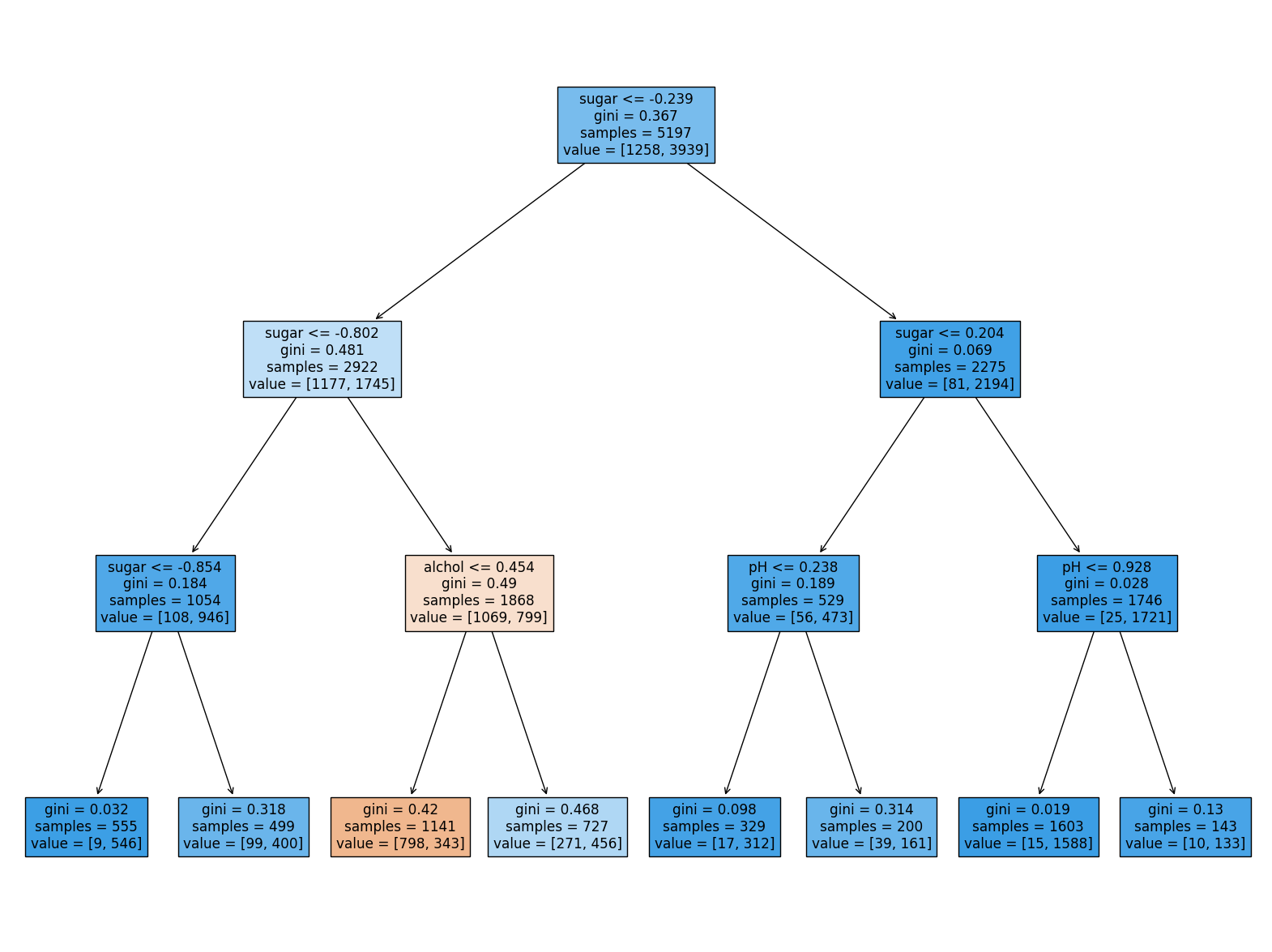

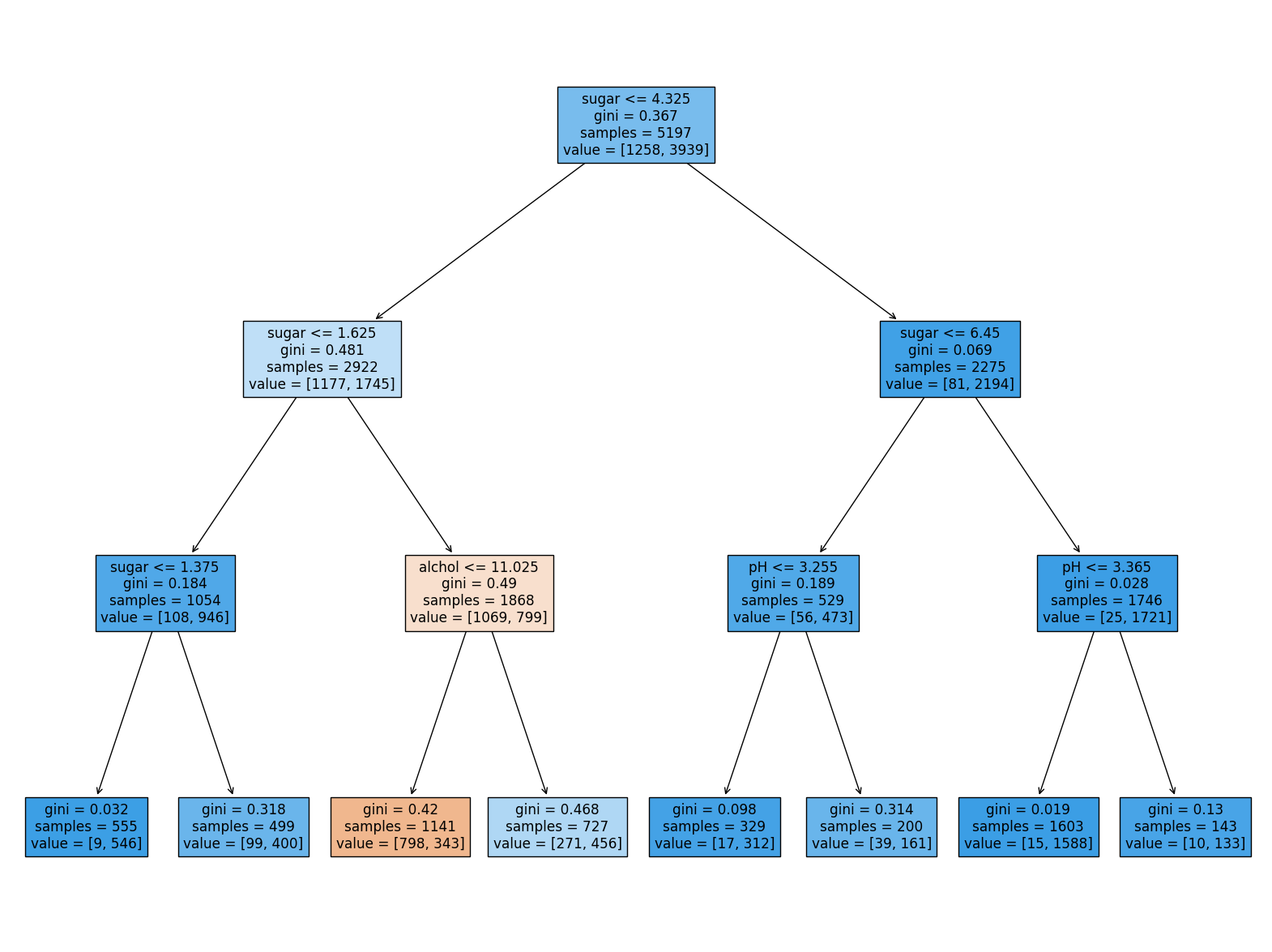
 01234567
01234567
pandas
- info(): 데이터프레임의 요약된 정보 출력
- 인덱스
- 컬럼 타입
- 널(null)이 아닌 값의 개수
- 메모리 사용량
- verbose 매개변수(default: True)
- False: 각 열에 대한 정보 출력 X
- describe(): 데이터프레임 열의 통계값 제공
- 수치형
- 최소, 최대, 평균, 표준편차, 사분위값
- 문자열(객체 타입의 열)
- 가장 자주 등장하는 값, 횟수 등
- percentiles 매개변수: 백분위수 지정
- default: 0.25, 0.5, 0.75
- 수치형
scikit-learn
- DecisionTreeClassifier: 결정 트리 분류 클래스
- criterion 매개변수: 불순도 지정
- default: gini
- 종류
- gini: 지니 불순도
- entropy: 엔트로피 불순도
- spliter 매개변수: 노드 분할 전략 지정
- default: best
- 종류
- best: 정보이득이 최대가 되도록 분할
- random: 임의로 노드 분할
- max_depth 매개변수: 트리가 성장할 최대 깊이 지정
- defaut: None
- 종류
- None: 리프 노드가 순수하거나 min_samples_split보다 샘플 개수가 적을때 까지 성장
- 숫자
- min_samples_split: 노드를 나누기 위한 최소 샘플 개수
- default: 2
- max_features 매개변수: 최적의 분할을 위해 탐색할 특성의 개수 지정
- default: None
- 종류
- None: 모든 특성 사용
- 숫자
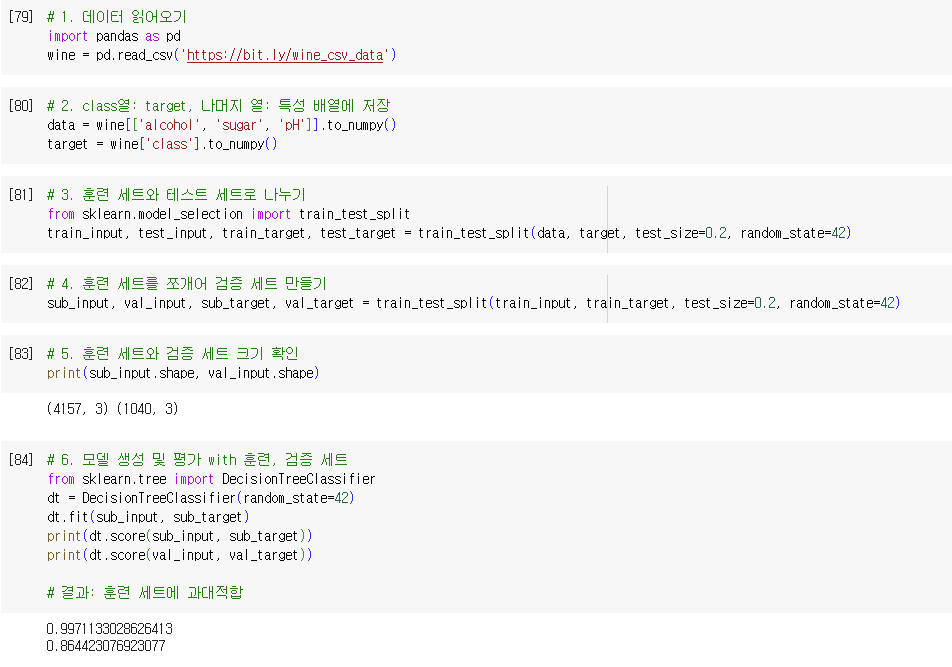
- criterion 매개변수: 불순도 지정
- plot_tree(): 결정 트리 모델 시각화
- 첫 번째 매개변수로 결정 트리 모델 객체 전달
- max_depth 매개변수: 트리의 깊이 지정
- default: None
- 종류
- None: 모든 노드 출력
- 숫자
- feature_names 매개변수: 특성의 이름 지정
- filled 매개변수: (True) 타깃값에 따라 노드 안에 색 채움
확인 문제
- 다음 중 결정 트리의 불순도에 대해 옳게 설명한 것을 모두 고르세요.
- 정답
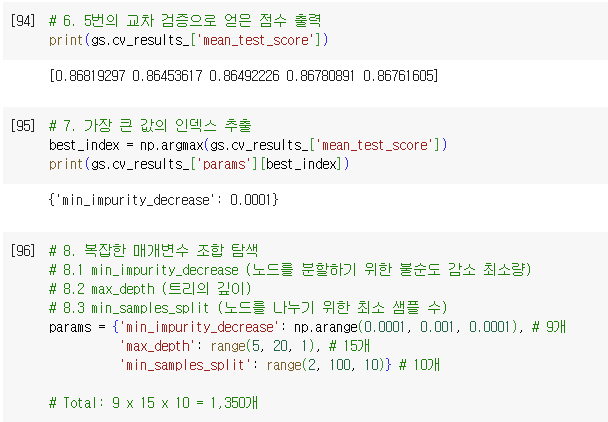
- 2번 / 지니 불순도는 클래스의 비율을 제곱하여 모두 더한 다음 1에서 뺍니다.
- 4번 / 엔트로피 불순도는 클래스 비율과 클래스 비율에 밑이 2인 로그를 적용한 값을 곱해서 모두 더한 후 음수로 바꾸어 계산합니다.
- 해설
- 1번 /
지니 불순도는정보 이득은 부모 노드의 불순도와 자식 노드의 불순도의 차이로 계산합니다. - 3번 /
엔트로피 불순도는 1에서 가장 큰 클래스 비율을 빼서 계산합니다.
- 1번 /
- 정답
- 결정 트리에서 계산한 특성 중요도가 저장되어 있는 속성은 무엇인가요?
- 정답: 4번 / feature_importances_
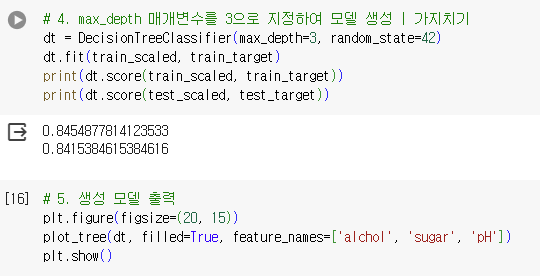
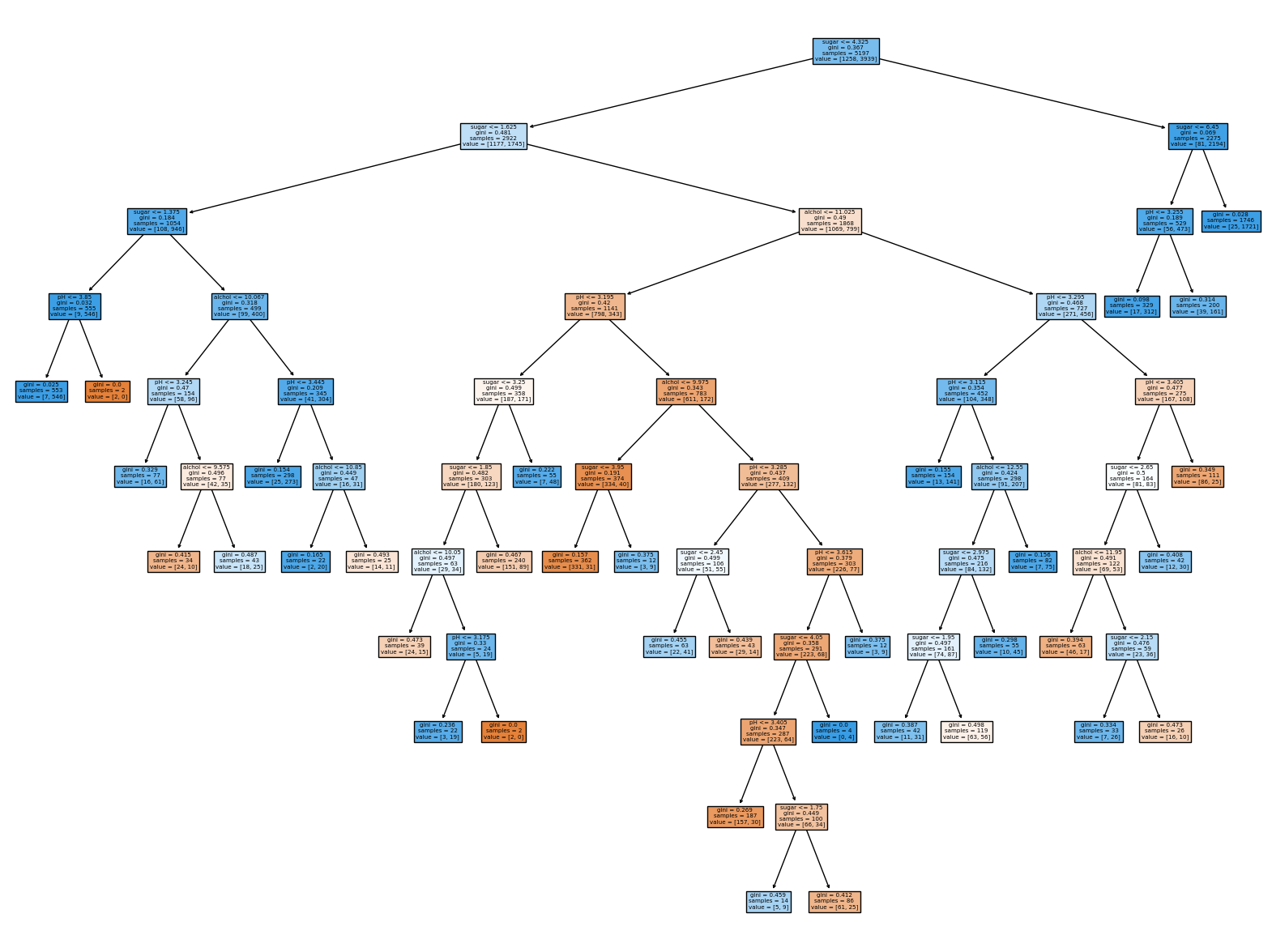
- 앞서 결정 트리 예제에서 max_depth를 3으로 지정하여 좌우가 대칭인 트리를 만들었습니다. 사이킷런의 결정 트리 클래스가 제공하는 매개변수 중 min_impurity_decrease를 사용해 가지치기를 해 보겠습니다. 어떤 노드의 정보 이득 x (노드의 샘플 수) / (전체 샘플 수) 값이 이 매개변수보다 작으면 더 이상 분할하지 않습니다. 이 매개변수의 값을 0.0005로 지정하고, 결정 트리를 만들어 보세요. 좌우가 균일하지 않은 트리가 만들어지나요? 테스트 세트의 성능은 어떤가요?
- 좌우가 균일하지 않은 트리 생성됨.
- 테스트 세트의 성능 높지 않음.

05-2 교차 검증과 그리드 서치 ▶ 검증 세트가 필요한 이유를 이해하고 교차 검증해 보기
학습 목표
- 검증 세트가 필요한 이유를 이해하고 교차 검증에 대해 배웁니다. 그리드 서치와 랜덤 서치를 이용해 최적의 성능을 내는 하이퍼파라미터를 찾습니다.
검증 세트(vaildation set) = 개발 세트(dev set)
- 훈련 세트를 더 쪼개 검증 세트로 활용
- 각 세트의 비율
- 훈련 세트: 60%
- 검증 세트: 20%
- 테스트 세트: 20%
- 사용 방법
- 모델 훈련: 훈련 세트
- 좋은 모델 선정: 검증 세트
- 재훈련: 훈련 + 검증 세트
교차 검증(cross vaildation)
- 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복
- ex. 3-폴드 교차 검증
- 훈련 세트: [ 파트 1 | 파트 2 | 파트 3]
- 훈련세트를 위와 같이 쪼개었을 때
- [훈련 세트 | 훈련 세트 | 검증 세트]
- [훈련 세트 | 검증 세트 | 훈련 세트]
- [검증 세트 | 훈련 세트 | 훈련 세트]
- 이와 같이 만들어 훈련 시킨 후 검증 점수 평균으로 최종 검증 점수를 얻는 방법

- 훈련세트를 위와 같이 쪼개었을 때
- 훈련 세트: [ 파트 1 | 파트 2 | 파트 3]
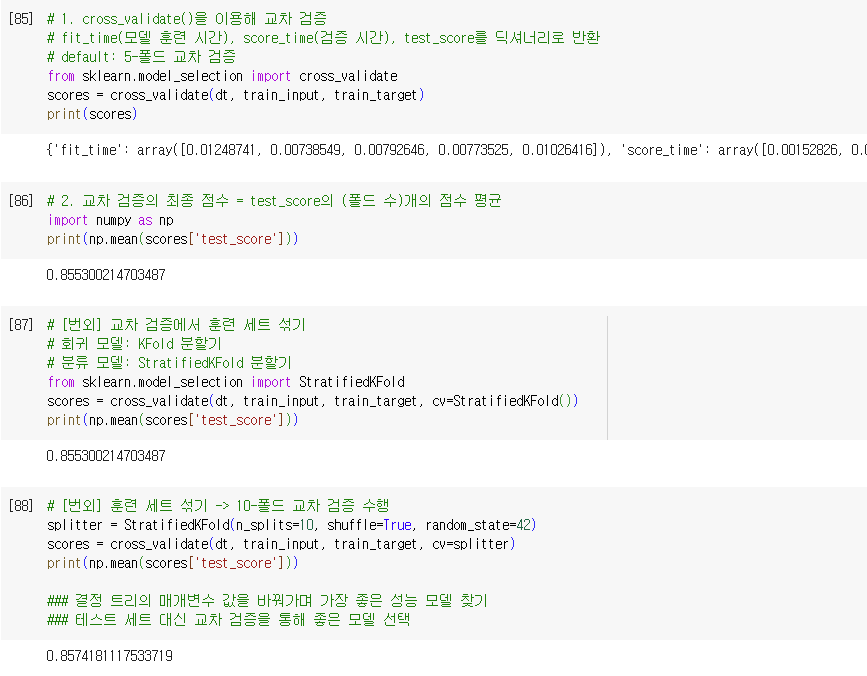
- cross_validate() 사용
- fit_time(모델 훈련 시간), score_time(검증 시간), test_score(검증 점수)를 딕셔너리로 반환
- default: 5 / 5-폴드 교차 검증 수행
- 최종 검증 점수 = test_score의 (폴드 수)개의 점수 평균
- 주의할 점
- cross_validate()은 훈련 세트를 섞어 폴드를 나누지 않음.
- 현재, train_test_split() 함수로 전체 데이터를 섞은 후 진행해서 필요는 없음.
- but, 교차 검증 시 훈련 세트를 섞으려면 분할기(splitter)를 지정해야 함.
- default
- 회귀 모델: KFold 분할기 사용
- 분류 모델: StratifiedKFold 분할기 사용
- default
- cross_validate()은 훈련 세트를 섞어 폴드를 나누지 않음.
하이퍼파라미터 튜닝
- 모델 파라미터: 머신러닝 모델이 학습하는 파라미터
- 하이퍼파라미터: 사용자 지정 파라미터(모델이 학습 불가)
- 최적의 값 찾기 ⇒ 그리드 서치 사용
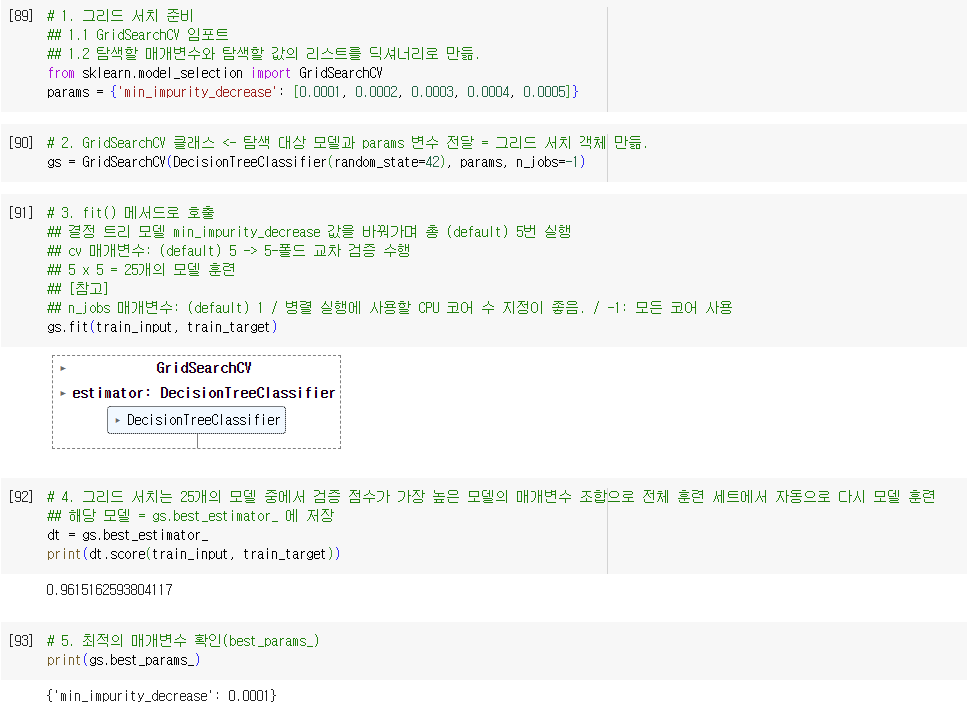
그리드 서치(Grid Search)
- 하이퍼파라미터 탐색 자동화 도구
- GridSearchCV 클래스
- 하이퍼파라미터 탐색 & 교차검증 제공
- so, cross_validate() 함수 호출 필요 X
- fit() 메서드: 모델 실행
- cv 매개변수: 교차 검증 수
- default: 5
- n_jobs 매갬변수: 사용할 CPU 수
- default: 1
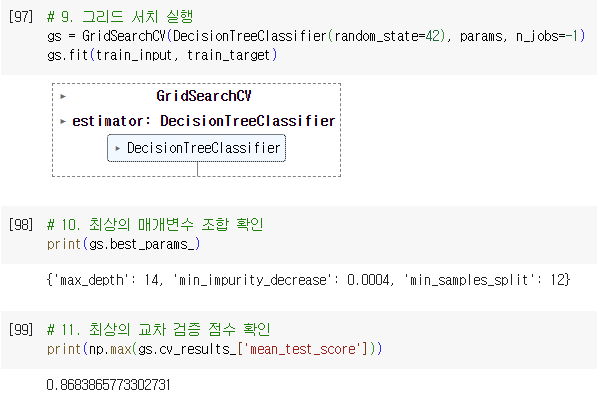
- 그리드 서치는 25개의 모델 중에서 검증 점수가 가장 높은 모델의 매개변수 조합으로 전체 훈련 세트에서 자동으로 다시 모델 훈련 → gs.best_estimator_
- 최적의 매개변수: best_params_
- 최상의 교차 검증 점수: np.max(gs.cv_results_[’mean_test_score’])
- 하이퍼파라미터 탐색 & 교차검증 제공
과정 정리
- 먼저 탐색할 매개변수 지정
- 훈련 세트에서 그리드 서치 수행 → 최상의 평균 검증 점수가 나오는 매개변수 조합 find → 그리드 서치 객체에 저장
- 그리드 서치: 최상의 매개변수에서 (교차 검증에 사용한 훈련 세트가 아니라) 전체 훈련 세트를 사용해 최종 모델 훈련 → 그리드 서치 객체에 저장
 012
012
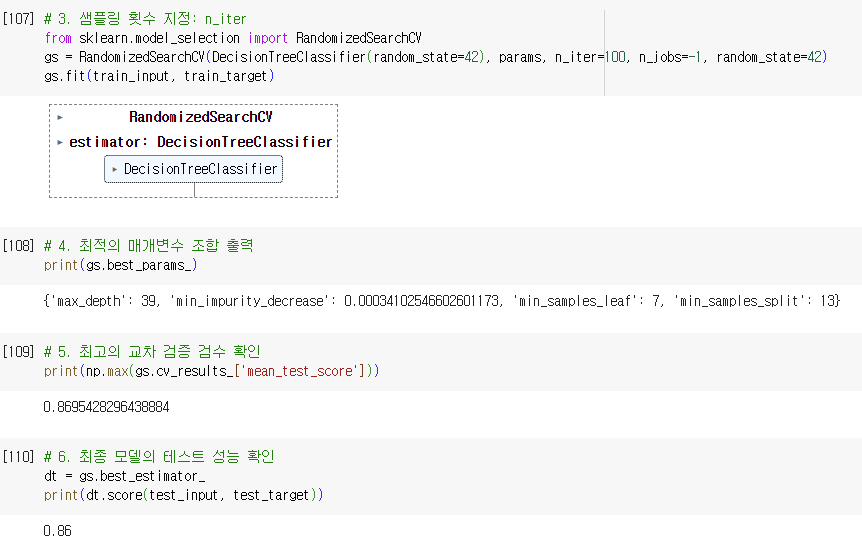
랜덤 서치(random serach)
- 사용 이유
- 매개변수의 값이 수치일 때 값의 범위나 간격을 미리 정하기 어려울 수 있음.
- 너무 많은 매개변수 조건이 있어 그리드 서치 수행 시간이 오래 걸림.
- 연속된 매개변수 값 탐색에 유용
- 랜덤 서치
- 매개변수의 값의 목록을 전달 X
- 매개변수를 샘플링 할 수 있는 확률 분포 객체 전달
- scipy의 확률 분포 클래스 활용
- 주어진 범위에서 고르게 값 추출
- uniform
- randint
- 주어진 범위에서 고르게 값 추출

 01
01
scikit-learn
- cross_validate(): 교차 검증을 수행하는 함수
- 첫 번째 매개변수: 교차 검증을 수행할 모델 객체 전달
- 두 번째 매개변수: 특성 데이터 전달
- 세 번째 매개변수: 타깃 데이터 전달
- scoring 매개변수: 검증에 사용할 평가지표 지정
- default
- 회귀 모델: accuracy (정확도)
- 분류 모델: r2 (결정계수)
- default
- cv 매개변수: 교차 검증 폴드 수/스플리터 객체 지정
- default
- 회귀 모델: KFold 클래스
- 분류 모델: StratifiedKFold 클래스
- default
- n_jobs 매개변수: 교차 검증을 수행할 때 사용할 CPU 코어 수 지정
- default: 1
- 모든 코어 사용: -1
- return_train_score 매개변수
- Default: False
- True: 훈련 세트의 점수도 반환
- GridSearchCV: 교차 검증으로 하이퍼파라미터 탐색 수행
- 최상의 모델을 찾은 후 훈련 세트 전체를 사용해 최종 모델 훈련
- 첫 번째 매개변수: 그리드 서치를 수행할 모델 객체 전달
- 두 번째 매개변수: 탐색할 모델의 매개변수와 값을 전달
- scoring, cv, n_jobs, return_train_score 매개변수는 cross_validate() 과 동일
- RandomizedSearchCV: 교차 검증으로 랜덤한 하이퍼파라미터 탐색 수행
- 최상의 모델을 찾은 후 훈련 세트 전체를 사용해 최종 모델 훈련
- 첫 번째 매개변수: 그리드 서치를 수행할 모델 객체 전달
- 두 번째 매개변수: 탐색할 모델의 매개변수와 확률 분포 객체 전달
- scoring, cv, n_jobs, return_train_score 매개변수는 cross_validate() 과 동일
확인 문제
- 훈련 세트를 여러 개의 폴드로 나누고 폴드 1개는 평가 용도로, 나머지 폴드는 훈련 용도로 사용합니다. 그다음 모든 폴드를 평가 용도로 사용하게끔 폴드 개수만큼 이 과정을 반복합니다. 이런 평가 방법을 무엇이라고 부르나요?
- 정답: 1번 / 교차 검증
- 다음 중 교차 검증을 수행하지 않는 함수나 클래스는 무엇인가요?
- 정답: 4번 / train_test_split
- 해설: 훈련 세트를 섞는 용도
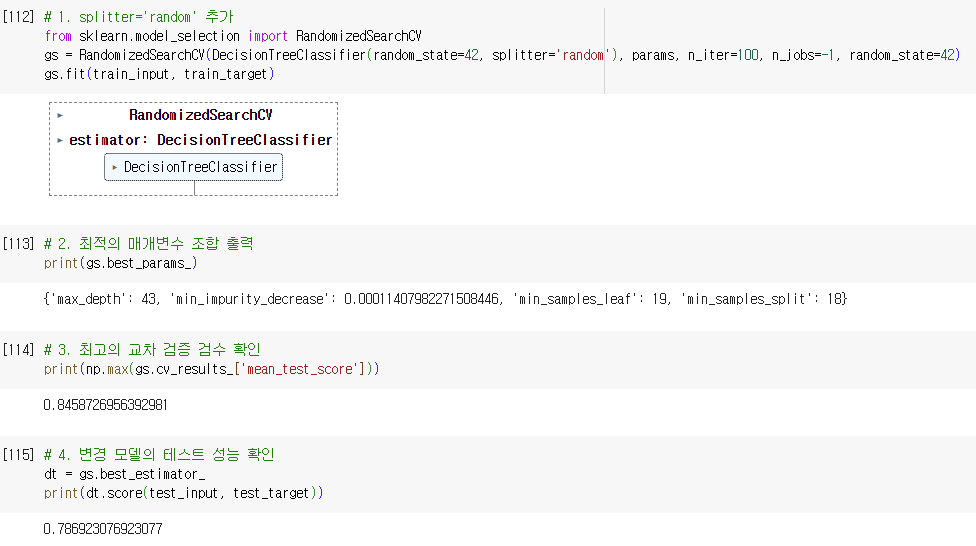
- 마지막 RandomizedSearchCV 예제에서 DecisionTreeClassifier 클래스에 spliter=’random’ 매개변수를 추가하고 다시 훈련해보세요. splitter 매개변수의 기본값은 ‘best’로 각 노드에서 최선의 분할을 찾습니다. ‘random’이면 무작위로 분할한 다음 가장 좋은 것을 고릅니다. 왜 이런 옵션이 필요한지는 다음 절에서 알 수 있습니다. 테스트 세트에서 성능이 올라갔나요? 내려갔나요?
- 성능이 내려감.
05-3 트리의 앙상블 ▶ 앙상블 학습을 알고 실습해 보기
학습 목표
- 앙상블 학습이 무엇인지 이해하고 다양한 앙상블 학습 알고리즘을 실습을 통해 배웁니다.
앙상블 학습
- 더 좋은 예측 결과를 만들기 위해 여러 개의 모델을 훈련하는 머신러닝 알고리즘
정형 데이터와 비정형 데이터
정형 데이터(structured data)
- 어떤 구조로 되어 있는
- ex. csv, database, excel…
- 정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘 → 앙상블 학습(ensemble learning)
비정형 데이터(unstructured data)
- DB나 Excel로 표현하기 어려운
- ex. 텍스트 데이터, 사진…
- 신경망 알고리즘
1. 랜덤 포레스트(Random Forest)
- 결정 트리를 랜덤하게 만들어 결정 트리(나무)의 숲을 만듦.
- 입력한 훈련 데이터에서 랜덤하게 샘플을 추출하여 훈련 데이터를 만듦.
- 이때 한 샘플이 중복되어 추출될 수 있음.
- 부트스트랩 샘플 사용
- 랜덤하게 일부 특성을 선택하여 트리를 만듦.
부트스트랩 샘플(bootstrap sample)
- 데이터 세트에서 중복을 허용하여 데이터를 샘플링 하는 방식
- 기본적으로 부트스트랩 샘플은 훈련 세트의 크기와 같게 만든다.
- 방법
- 예를 들어, 1,000개 가방에서 100개씩 샘플을 뽑는다면 먼저 1개를 뽑고, 뽑았던 1개를 다시 가방에 넣는다.
- 이런 식으로 계속해서 100개 가방에서 뽑으면 중복된 샘플을 뽑을 수 있다.
- 각 노드를 분할할 때 전체 특성 중에서 일부 특성을 무작위로 고른 다음 이 중에서 최선의 분할을 찾는다.
- 분류 모델인 RandomForestClassifier는 기본적으로 전체 특성 개수의 제곱근만큼의 특성을 선택합니다.
- 즉 4개의 특성이 있다면 노드마다 2개를 랜덤하게 선택하여 사용합니다.
- 다만, 회귀 모델인 RandomForestRegressor는 전체 특성을 사용합니다.
- 사이킷런의 랜덤 포레스트는 기본적으로 100개의 결정 트리를 이런 방식으로 훈련합니다.
- 그다음 분류일 때는 각 트리의 클래스별 확률을 평균하여 가장 높은 확률을 가진 클래스를 예측으로 삼습니다.
- 회귀일 때는 단순히 각 트리의 예측을 평균합니다.
돌아 보기
- 분류: 샘플을 몇 개의 클래스 중 하나로 분류하는 문제
- 회귀: 임의의 어떤 숫자를 예측하는 문제
- 장점
- (랜덤하게 선택한 샘플과 특성을 사용하기 때문에)
- 훈련 세트에 과대적합되는 것을 막아줌.
- 검증 세트와 테스트 세트에서 안정적인 성능 확보
- RandomForestClassifier
- 기본적으로 100개의 결정 트리를 사용하므로, n_jobs 매개변수를 -1로 지정하여 모든 CPU 코어를 사용하는 것이 좋음.
- 결정 트리의 앙상블이므로 DecisionTreeClassifier가 제공하는 중요한 매개변수 모두 제공함.
- criterion
- max_depth
- max_features
- min_samples_split
- min_impurity_decrease
- min_samples_leaf 등
- 랜덤 포레스트의 특성 중요도
- 각 결정 트리의 특성 중요도를 취합한 것
- 기능
- 자체적으로 모델을 평가하는 점수 획득 가능
- OOB(out of bag) 샘플
- 부트스트랩 샘플에 포함되지 않고 남는 샘플
- 이 샘플로 부트스트랩 샘플로 훈련한 결정 트리 평가 가능(like 검증 세트)
- 이 점수를 얻으려면 oob_score 매개변수 = True 지정
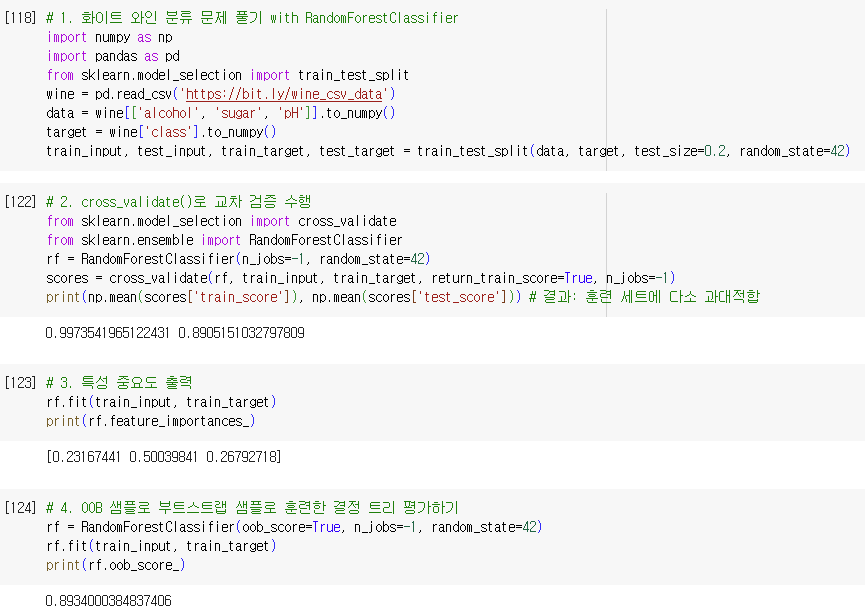
2. 엑스트라 트리(Extra Trees)
- 랜덤 포레스트와 매우 비슷하게 동작
- 기본적으로 100개의 결정 트리 훈련
- 랜덤 포레스트와 같이 결정 트리가 제공하는 대부분의 매개변수 지원
- 전체 특성 중에 일부 특성을 랜덤하게 선택하여 노드를 분할하는 데 사용
- 랜덤 포레스트와 차이점
- 부트스트랩 샘플을 사용 X
- 즉각 결정 트리를 만들 때 전체 훈련 세트 사용
- 대신 노드를 분할할 때 가장 좋은 분할을 찾는 것이 아니라 무작위로 분할
- 엑스트라 트리가 사용하는 결정 트리 splitter=’random’인 결정 트리
- 무작위 분할로 랜덤 포레스트보다 속도가 빠름.
- 하나의 결정 트리에서 특성을 무작위로 분할 → 성능 하락
- But, 많은 트리를 앙상블 하기 때문에 과대적합을 막고 검증 세트의 점수 증가 효과
- 엑스트라 트리의 회귀 버전 = ExtraTreesRegressor 클래스

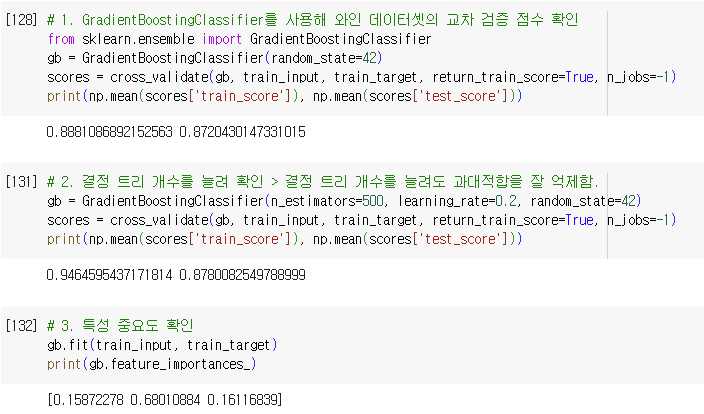
3. 그레이디언트 부스팅(gradient boosting)
- 깊이가 얇은 결정 트리를 사용하여 이진 트리의 오차를 보완하는 방식에 앙상블 방법
- GradientBoostingClassifier
- 기본적으로 깊이가 3인 결정 트리 100개 사용
- 경사하강법을 사용하여 트리를 앙상블에 추가
- 분류: 로지스틱 손실 함수 사용
- 회귀: 평균 제곱 오차 함수 사용
- 결정 트리를 계속 추가하면서 가장 낮은 곳을 찾아 이동
- 결정 트리의 개수를 늘려도 과대 적합에 매우 강함.
- 학습률을 증가시키고 트리의 개수를 늘리면 조금 더 성능 향상 가능
- 결정 트리 개수를 늘려도 과대적합을 잘 억제함.
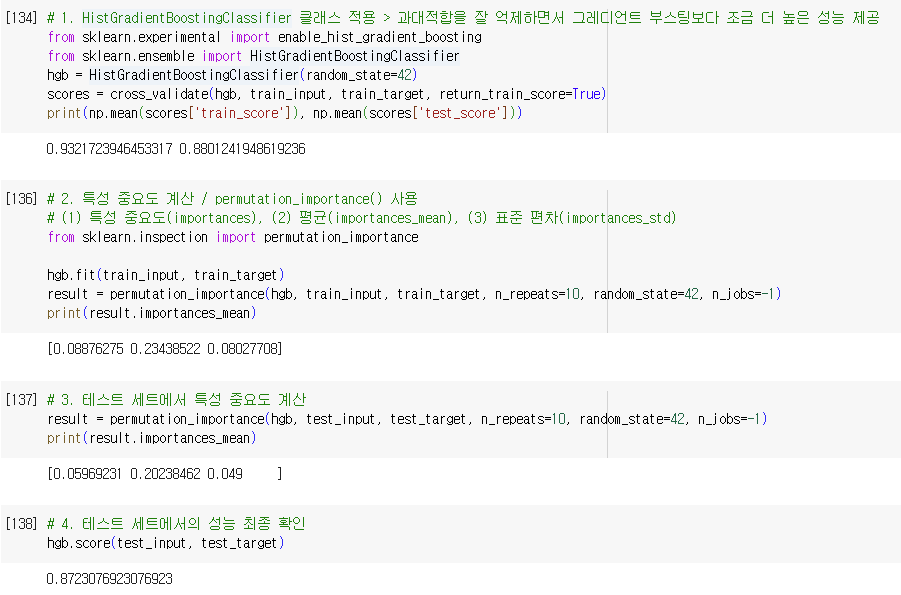
4. 히스토그램 기반 그레디언트 부스팅(histogram based Gradient Boosting)
- 정형 데이터를 다루는 머신러닝 알고리즘 중에 가장 인기가 높은 알고리즘
- 먼저 입력 특성을 256개의 구간으로 나눔
- 따라서 노드를 분할할 때 최적의 분할을 매우 빠르게 찾을 수 있음.
- 256개의 구간 중에서 하나를 떼어 놓고 누락된 값을 위해서 사용
- 따라서 입력에 누락된 특성이 있더라도 이를 따로 전처리할 필요가 없음.
- HistGradientBoostingClassifier
- max_iter 매개변수: 트리의 개수 지정(n_estimators 매개변수 대신)
- 특성 중요도 계산: permutation_importance()
- 특성을 하나씩 랜덤하게 섞어서 모델의 성능이 변화하는지를 관찰하여 어떤 특성이 중요한지 계산
- 훈련 세트, 테스트 세트에도 적용 가능
- 사이킷런에서 제공하는 추정기 모델에 모두 사용 가능
- n_repeats 매개변수: 랜덤하게 섞을 횟수 지정
- 히스토그램 기반 그레디언트 부스팅
- 사이킷런
- 분류: HistGradientBoostingClassifier
- 회귀: HistGradientBoostingRegressor
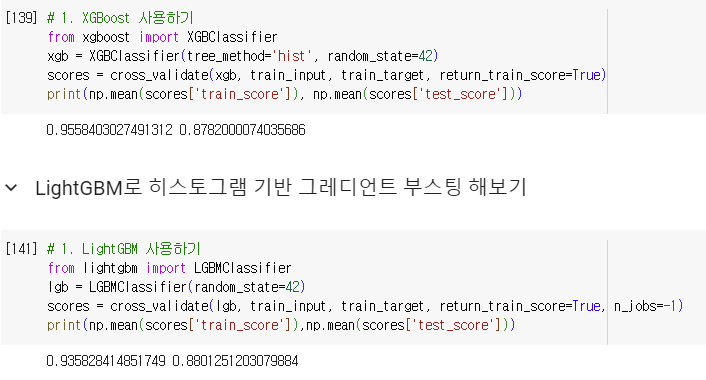
- XGBoost
- cross_validate() 함수도 함께 사용 가능
- tree_method 매개변수
- hist: 히스토그램 기반 그레디언트 부스팅 사용
- LightGBM
- 사이킷런
 01
01
scikit-learn
- RandomForestClassifier: 랜덤 포레스트 분류 클래스
- n_estimators 매개변수: 앙상블을 구성할 트리의 개수 지정
- default: 100
- criterion 매개변수: 불순도 지정
- default: gini
- entropy
- max_depth 매개변수: 트리가 성장할 최대 깊이 지정
- default: None
- 리프노드가 순수하거나 min_samples_split보다 샘플 개수가 적을 때까지 성장
- default: None
- min_samples_split 매개변수: 노드를 나누기 위한 최소 샘플 개수
- default: 2
- max_features 매개변수: 최적의 분할을 위해 탐색할 특성의 개수 지정
- deafult: auto
- 특성 개수의 제곱근
- deafult: auto
- bootstrap 매개변수: 부트스트랩 샘플 사용 여부 지정
- default: True
- oob_score: OOB 샘플을 사용하여 훈련한 모델을 평가할지 지정
- default: False
- n_jobs 매개변수: 병렬 실행에 사용할 CPU 코어 수 지정
- default: 1
- -1: 시스템에 있는 모든 코어 사용
- n_estimators 매개변수: 앙상블을 구성할 트리의 개수 지정
- ExtraTreesClassifier: 엑스트라 트리 분류 클래스
- RandomForestClassifier의 매개변수와 동일.
- GradientBoostingClassifier: 그레이디언트 부스팅 분류 클래스
- loss 매개변수: 손실 함수 지정
- default: deviance(로지스틱 손실 함수)
- learning_rate 매개변수: 트리가 앙상블에 기여하는 정도 조절
- default: 0.1
- n_estimators 매개변수: 부스팅 단계를 수행하는 트리의 개수
- default: 100
- subsample 매개변수: 사용할 훈련 세트의 샘플 비율 지정
- default: 1.0
- max_depth 매개변수: 개별 회귀 트리으 ㅣ최대 깊이
- default: 3
- loss 매개변수: 손실 함수 지정
- HistGradientBoostingClassifier: 히스토그램 기반 그레이디언트 부스팅 분류 클래스
- learning_rate 매개변수: 학습률 또는 감쇠율
- 기본값: 0.1
- 1.0: 감쇠가 전혀 없음.
- max_iter: 부스팅 단계를 수행하는 트리의 개수
- default: 100
- max_bins: 입력 데이터를 나눌 구간의 개수
- default: 255(최대 수치)
- 여기에 1개의 구간이 누락된 값을 위해 추가됨.
- default: 255(최대 수치)
- learning_rate 매개변수: 학습률 또는 감쇠율
확인 문제
- 여러 개의 모델을 훈련시키고 각 모델의 예측을 취합하여 최종 결과를 만드는 학습 방식을 무엇이라고 부르나요?
- 정답: 4번 / 앙상블 학습
- 다음 중 비정형 데이터에 속하는 것은 무엇인가요?
- 정답: 4번 / 이미지 데이터
- 다음 알고리즘 중 기본적으로 부트스트랩 샘플을 사용하는 알고리즘은 무엇인가요?
- 정답: 1번 / 랜덤 포레스트
4주차 혼공학습단 소감
지난 주에 비해 내용이 많기는 했으나, 트리를 시각화 해봄으로써 재밌게 학습할 수 있는 주차였다. 확실히 학습을 거듭할수록 라이브러리 구현이 잘 되어 있어, 학습에 어려움이 덜했다. 더군다나 매개변수의 사용도 거의 동일해서 반복 학습의 느낌도 들었다. 다음 주도 기대가 된다.
손 코딩 자료
반응형
'코딩 | 개념 정리 > Machine Learning & Deep Learning' 카테고리의 다른 글
| [혼공머신] 6주차_딥러닝을 시작합니다. (0) | 2024.02.11 |
|---|---|
| [혼공머신] 5주차_비지도 학습 (0) | 2024.02.03 |
| [혼공머신] 3주차_다양한 분류 알고리즘 (0) | 2024.01.20 |
| [혼공머신] 2주차_회귀 알고리즘과 모델 규제 (0) | 2024.01.13 |
| [혼공머신] 1주차_인공지능 기초와 데이터 처리 (3) | 2024.01.06 |