

지난 10기는 기한을 놓쳐 신청을 못했지만, 1년을 기다려 이번엔 혼공학습단 11기에 성공적으로 안착했다. 혼공 시리즈 다른 책들은 이미 많이 봐온 만큼 이번에는 '혼자 공부하는 머신러닝+딥러닝'을 통해 애매한 포지션을 잡고 있었던 인공지능을 정복하고자 한다.
Chapter 01 나의 첫 머신러닝
01-1. 인공지능 > 머신러닝 > 딥러닝

인공지능
위 3가지는 이 책 뿐만 아니라, 2016년 3월 알파고나 나온 이후로 ChatGPT와 함께 대중들이 한 번쯤 들어봤을 용어이다. 하지만, 전공자가 아닌 이상 이 셋을 명확히 구분하기는 힘들 것이다. AI의 학술적인 이론은 1943년부터 나온 이론으로서 인간의 뇌를 모방하여 뉴런을 컴퓨터 시스템으로서 구현하여 말 그대로 인공적인 자아를 만드는 데 있다. 결국 인공지능이라는 것은 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술을 총칭한다.

인공지능은 그 수준에 따라 약인공지능 vs. 강인공지능으로 분류가 된다. SAMSUNG SDS의 글을 참고하면 아래와 같이 분류할 수 있다.
- 약인공지능: 특정 영역의 전문가, 약한 인공지능
- 강인공지능: 자신만의 자아를 가지고 있는 강한 인공지능
머신러닝

이제 이러한 인공지능에서 조금 더 깊게 들어가면 머신러닝이 등장합니다. 머신러닝? 영어로만 봐서는 잘 와닿지 않는다. 기계학습이라고 번역을 하면 한층 더 이해하기 쉬운 학문이다. 인공지능에 사람들이 열광하는 이유는 무엇일까요? 바로 ‘자동화’ 일 것이다. 내가 손을 대지 않아도 명령 하나만으로 자동으로 일을 수행하고 답을 해주는 이러한 특장점 때문에 사람들은 매료되었다. 이러한 것의 모든 뿌리가 되는 학문이 머신러닝, 기계학습이다. 결국 ‘데이터를 보고 자동으로 규칙을 학습하는 알고리즘’을 연구하는 분야가 머신러닝이다. 규칙 하면 수학 → 통계학으로 이어지죠. 따라서 통계학 쪽에서는 통계 계산과 그래픽을 위한 프로그래밍 언어인 R을 활용하기도 하며, ADsP, ADP, 빅데이터분석기사 등에서도 Python과 함께 사용되고 있다.
수학적인 이론을 일일이 일반인이 손수 프로그램화 한다면 정말 시간도 오래 걸리고, 쉽사리 도전하지 못할 것이다. 하지만, 오픈소스의 바람과 함께 Python의 대표적인 머신러닝 라이브러리인 사이킷런을 활용하면 단 몇 분만에 머신러닝을 구현할 수 있다. 따라서, 입문자의 문턱을 낮추어 누구나 손쉽게 머신러닝을 구현할 수 있다. 물론 머신러닝을 제대로 돌리기 위해서는 CPU/GPU 자원이 필요한데, 이는 구글 코랩(Colab)을 통해 학습 수준에서는 해결할 수 있다.
딥러닝

딥러닝은 머신러닝 중에서도 거미줄처럼 퍼진 우리의 신경망 혹은 우리의 뇌 구조를 구현하기 위해 인공 신경망을 주로 다루는 학문이다. 따라서, 앞서 설명한 머신러닝보다 강인공지능에 가깝게 다가갈 수 있는 학문이다. 여기까지 설명했을 때 머신러닝과 딥러닝은 별차이 없는 것처럼 보인다. 둘 다 ‘데이터를 보고 규칙을 학습해 결론을 추론한다’는 것은 같다. 하지만, 머신러닝은 이러한 데이터 처리 과정(패턴 추출)을 인간이 하는 반면, 딥러닝은 정말 사람처럼 데이터 처리 과정(패턴 추출)까지 컴퓨터가 처리하여 스스로 학습을 할 수 있다는 정말 큰 강점을 가지고 있다. 딥러닝도 역시 머신러닝과 같이 라이브러리가 존재한다. 대표적으로 2가지 인데, 구글에서 공개한 Tensorflow, 페이스북(現 메타)에서 공개한 Pytorch가 있다.
01-2. 코랩과 주피터 노트북
앞서 밝힌 바와 같이 머신러닝과 딥러닝을 위한 학습을 위해서는 CPU/GPU 환경이 필수적이다. 클라우드 서비스가 활발해지면서 구글에서는 이러한 장벽을 허물고자, 구글 클라우드와 연결하여 구글 코랩 서비스를 출시했다. 물론 이것도 무료로 사용하는데는 한계가 있지만, 개인적인 학습용이라면 충분하다. 나는 기본적으로 어떠한 툴을 익힐 때면 되도록이면 마우스를 사용하고 싶지 않아서, 아래와 같이 단축키를 정리해보았다. 이보다 더 많은 단축키는 코랩에서 도구 > 단축키( Ctrl + M + H )를 눌러보자.
단축키
- 코드 셀 전환: Ctrl + M + A
- 텍스트 셀 전환: Ctrl + M + M
- 실행 단축키
- 셀 실행: Ctrl + Enter
- 셀 실행 후 다음 셀 선택: Shift + Enter
- 셀 실행 후 다음 셀 삽입: Alt + Enter
- 줄번호 표시: Ctrl + M + L
확인 문제
1. 구글에서 제공하는 웹 브라우저 기반의 파이썬 실행 환경은 무엇인가요?
- 정답: 2번 / 코랩
2. 코랩 노트북에서 쓸 수 있는 마크다운 중에서 다음 중 기울임 꼴로 쓰는 것은?
- 정답: 4번 / _혼공머신_
3. 코랩 노트북은 어디에서 실행되나요?
- 정답: 3번 / 구글 클라우드
01-3. 마켓과 머신러닝
훈련
데이터에서 규칙을 찾는 과정
산점도
산점도는 x, y축으로 이뤄진 좌표계에 두 변수(x, y)의 관계를 표현하는 방법이다.


k-최근접 이웃(k-Nearest Neighbors) 알고리즘
주변에서 가장 가까운 N개의 데이터를 보고 다수결의 원칙에 따라 데이터를 예측한다.


from ~ import 구문
파이썬에서 패키지나 모듈 전체를 임포트하지 않고 특정 클래스만 임포트하는 방법
matplotlib
- scatter(): 산점도를 그리는 맷플롯립 함수
scikit-learn
- KNeighborsClassifier(): k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스
- fit(): 사이킷런 모델을 훈련할 때 사용하는 메서드
- predict(): 사이킷런 모델을 훈련하고 예측할 때 사용하는 메서드
- score(): 훈련된 사이킷런 모델의 성능 측정
확인 문제
- 데이터를 표현하는 하나의 성질로써, 예를 들어 국가 데이터의 경우 인구 수, GDP, 면적 등이 하나의 국가를 나타냅니다. 머신러닝에서 이런 성질을 무엇이라고 부르나요?
- 정답: 1번 / 특성(feature)
- 가장 가까운 이웃을 참고하여 정답을 예측하는 알고리즘이 구현된 사이킷런 클래스는 무엇인가요?
- 정답: 4번 / KNeighborsClassifier
- 사이킷런 모델을 훈련할 대 사용하는 메서드는 어떤 것인가요?
- 정답: 2번 / fit()
Chapter 02 데이터 전처리
02-1. 훈련 세트와 테스트 세트
데이터 구분

- 훈련 세트(train set): 모델을 훈련시키는 용도
- 테스트 세트(test set): 모델을 평가하기 위한 용도
- 사이킷런의 입력 데이터(배열)의 구성
- 행(샘플) / 열(특성)
머신러닝 알고리즘
- 지도 학습(supervised learning)
- 데이터(입력) + 정답(타깃)으로 훈련
- 비지도 학습(unsupervised learning):
- 데이터(입력)만으로 훈련
- 강화 학습(rainforce learning)
- 데이터(입력) + 보상(알고리즘이 행동한 결과로 얻은)
샘플링 편향(sampling bias)
- 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않은 경우
넘파이

- 파이썬의 대표적인 배열 라이브러리
- 추가 기능
- 배열 인덱싱
- seed(): 난수를 생성하기 위한 초깃값 지정
- arrange(): 일정한 간격의 정수 또는 실수 배열 생성
- suffle(): 주어진 배열을 랜덤하게 섞음
- 브로드캐스팅: 배열 간 자동 사칙연산
- 참고 사항: 사이킷런 모델의 입력과 출력은 모두 넘파이 배열
확인 문제
- 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은 무엇인가요?
- 정답: 1번 / 지도학습
- 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요?
- 정답: 4번 / 샘플링 편향
- 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
- 정답: 2번 / 행: 샘플, 열: 특성
02-2 데이터 전처리
Matplot marker list
matplotlib.markers — Matplotlib 3.8.2 documentation
데이터 전처리의 필요성
- k-최근접 이웃 알고리즘과 같이 샘플 간의 거리에 영향을 많이 받는 알고리즘의 경우 제대로 사용하기 위해서 특성값을 일정한 기준으로 맞춰 주어야 한다.
- 즉, 이번 예제와 같이 특성 1: length, 특성 2: weigth은 서로 측정 기준이 다르므로 표준점수를 활용해 그 수치 비율을 맞춰주는 것이다.
데이터 전처리 방법 1 | 표준점수(standard scroe)

- 표준점수: 각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지
- 이를 통해 실제 특성값의 크기와 상관없이 동일한 조건으로 비교 가능
- 주의사항

scikit-learn
- train_test_split(): 훈련 데이터와 테스트 세트로 나누는 함수
- kneighbors(): k-최근접 이웃 객체의 메서드
데이터 전처리 결과 비교
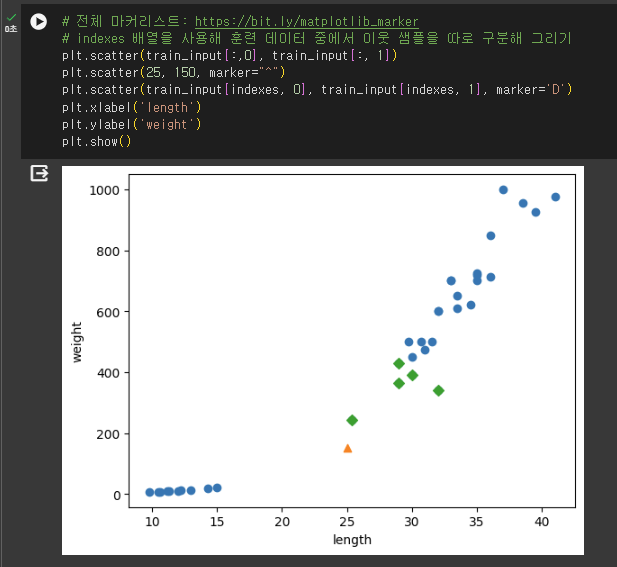

확인 문제
- 이 방식은 스케일 조정 방식의 하나로 특성값을 0에서 표준편차의 몇 배수만큼 떨어져 있는 지로 변환한 값입니다. 이 값을 무엇이라 부르나요?
- 정답: 3번 / 표준점수
- 테스트 세트의 스케일을 조정하려고 합니다. 다음 중 어떤 데이터의 통계 값을 사용해야 하나요?
- 정답: 1번 / 훈련세트
-
- 정답: 1번 / 훈련세트
혼공학습단 1주차 소감
나는 전공자이기도 하며, 이미 작년에 ADsP를 자격증을 취득하면서 인공지능에 대해서는 조금 이나마 견문이 있는 상태이다. 하지만, 인공지능은 공부할수록 아직 기본이 부족하다는 생각이 많이 들었다. 첫 1주차는 이러한 기본을 닦는 토대가 되는 장으로서 인공지능에 대해 나만의 언어로 정리하고, 데이터 전처리 과정을 복습할 수 있는 시간이 되었다. 이처럼 남은 기간도 성실히 임하여 인공지능을 나의 것으로 만들고 싶다.
손코딩 자료
참고자료
[AI란 무엇인가] 인공지능 머신러닝 딥러닝 차이점 총정리 혼자 공부하는 책
강한 인공지능 VS 약한 인공지능 | 인사이트리포트 | 삼성SDS
'코딩 | 개념 정리 > Machine Learning & Deep Learning' 카테고리의 다른 글
| [혼공머신] 6주차_딥러닝을 시작합니다. (0) | 2024.02.11 |
|---|---|
| [혼공머신] 5주차_비지도 학습 (0) | 2024.02.03 |
| [혼공머신] 4주차_트리 알고리즘 (0) | 2024.01.27 |
| [혼공머신] 3주차_다양한 분류 알고리즘 (0) | 2024.01.20 |
| [혼공머신] 2주차_회귀 알고리즘과 모델 규제 (0) | 2024.01.13 |