코딩 | 개념 정리/Machine Learning & Deep Learning
[혼공머신] 3주차_다양한 분류 알고리즘
PatienceLee
2024. 1. 20. 21:23

Chapter 04 다양한 분류 알고리즘 ▶ 럭키백의 확률을 계산하라!
04-1 로지스틱 회귀 ▶ 로지스틱 회귀 알고리즘을 배우고 이진 분류 문제에서 클래스 확률 예측하기
학습목표
- 로지스틱 회귀, 확률적 경사 하강법과 같은 분류 알고리즘을 배웁니다.
- 이진 분류와 다중 분류의 차이를 이해하고 클래스별 확률을 예측합니다.
럭키백의 확률
데이터프레임
- 판다스에서 제공하는 2차원 표 형식의 주요 데이터 구조
- 넘파이 배열과 비슷하게 열과 행으로 이루어짐
다중 분류
- 타깃 데이터에 2개 이상의 클래스가 포함된 문제
로지스틱 회귀(logistic regression)
- 회귀이지만 분류모델
- 선형 회귀와 동일하게 선형 방정식을 학습
z = a *(Weight) + b * (Length) + c * (Diagonal) + d * (Height) + e * (Width) + f
- 가중치 혹은 계수: a, b, c, d, e
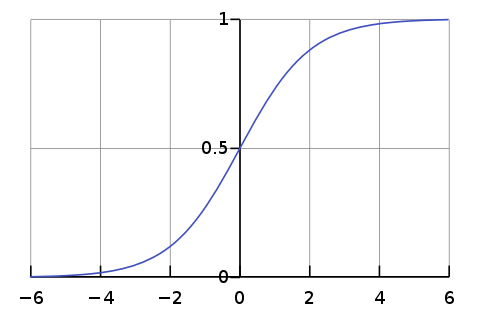
- 시그모이드 함수(sigmoid function) or 로지스틱 함수(logistic function)
- z 가 아주 큰 음수일 때 0이 되고, z 가 아주 큰 양수일 때 1이 되도록 바꿈
- 즉, 0~1 사이 값을 0~100%까지 확률로 해석 가능
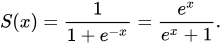

- 지수 함수 계산
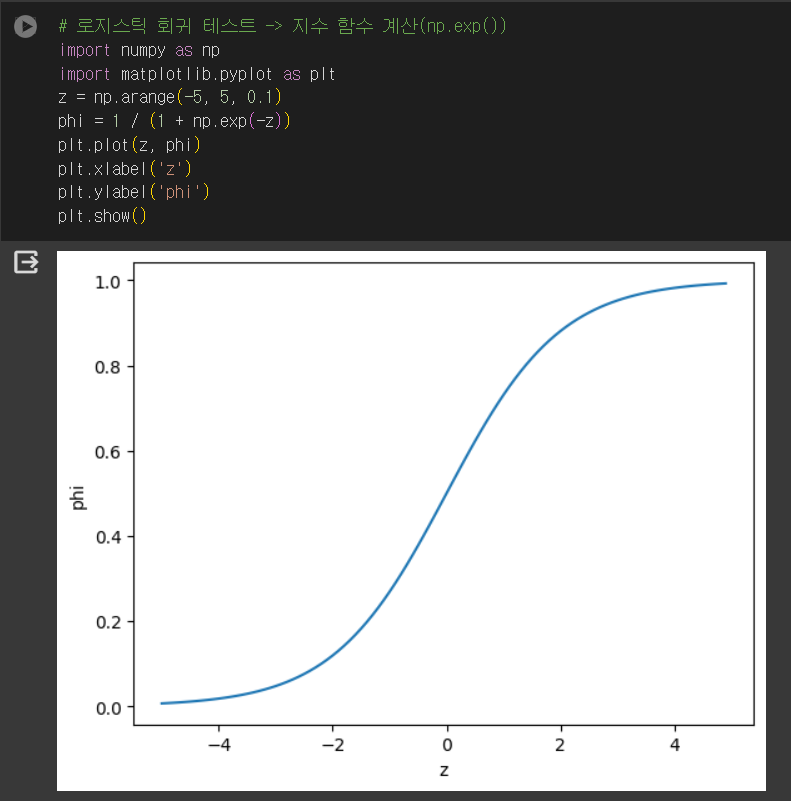
로지스틱 회귀로 이진 분류 수행하기

로지스틱 회귀 모델 훈련 및 결과 출력

확률값 확인하기
- 방법 1. np.exp() 함수를 사용해 분수 계산
- 방법 2. expit() / 훨씬 더 간편

 01
01
로지스틱 회귀로 다중 분류 수행하기
- LogisticRegression 클래스
- 기본적으로 반복적인 알고리즘 사용
- max_iter 매개변수에서 반복 횟수 지정(default = 100)
- 기본적으로 릿지 회귀와 같이 계수의 제곱을 규제(L2 규제)
- 규제의 양 조절
- 릿지 회귀: alpha 매개변수 → 클수록 규제 커짐
- 로지스틱 회귀: C 매개변수 → 작을수록 규제 커짐
- 규제의 양 조절
- 기본적으로 반복적인 알고리즘 사용
- 예시
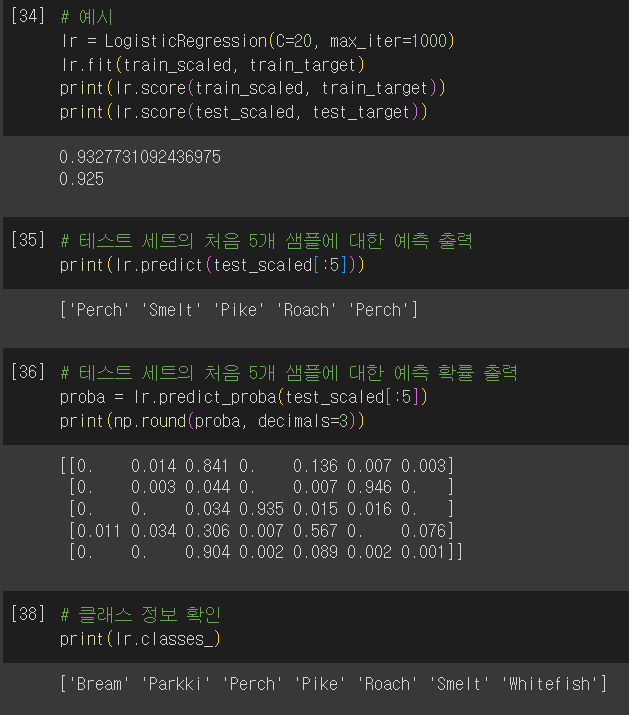
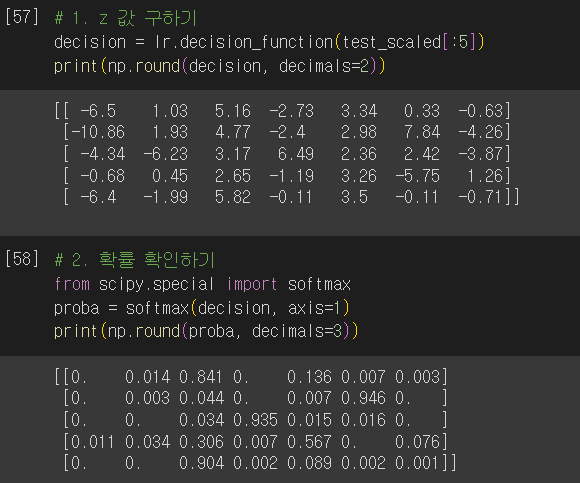
- 다중 분류는 클래스마다 z 값을 하나씩 계산
- 높은 z 값을 출력하는 클래스 = 예측 클래스
- 확률 계산 방법은?
- 이진 분류: 시그모이드 함수 → 하나의 선형 방정식의 출력값을 0~1 사이로 압축
- 다중 분류: 소프트맥스 함수 → 여러 개의 선형 방정식의 출력값을 0~1 사이로 압축
- 정규화된 지수 함수

scikit-learn
- LogisticRegression
- 선형 분류 알고리즘인 로지스틱 회귀를 위한 클래스
- solver 매개변수에서 사용할 알고리즘 선택 가능
- default = lbfgs
- sag: 확률적 평균 경사 하강법 알고리즘(특성과 샘플 수가 많을 때 Good)
- saga: sag 개선 버전
- default = lbfgs
- penalty 매개변수에서 규제 방식 선택 가능
- default = l2
- l1: L1 규제(라쏘 방식)
- l2: L2 규제(릿지 방식)
- default = l2
- C 매개변수 규제의 강도 제어 가능
- default = 1.0
- 값이 작을수록 규제가 강해짐.
- default = 1.0
- predict_proba(): 예측 확률 반환
- 이진 분류: 음성/양성 클래스에 대한 확률 반환
- 다중 분류: 샘플 마다 모든 클래스에 대한 확률 반환
- decision_function(): 선형 방정식의 출력 반환
- 이진 분류: 양성 클래스의 확률 반환
- 확률 > 0 ? ‘양성 클래스’ : ‘음성 클래스’
- 다중 분류: 각 클래스마다 선형 방정식 계산
- 가장 큰 값의 클래스가 예측 클래스
- 이진 분류: 양성 클래스의 확률 반환
확인 문제
- 2개보다 많은 클래스가 있는 분류 문제를 무엇이라 부르나요?
- 정답: 2번 / 다중 분류
- 로지스틱 회귀가 이진 분류에서 확률을 출력하기 위해 사용하는 함수는 무엇인가요?
- 정답: 1번 / 시그모이드 함수
- 해설: 이진 분류 → 시그모이드 함수 / 다중 분류 → 소프트맥스 함수
- decision_function() 메서드의 출력이 0일 때 시그모이드 함수의 값은 얼마인가요?
- 정답: 3번 / 0.5
- 해설: 시그모이드 그래프를 보면 단 번에 이해가 갈 것이다.
04-2 확률적 경사 하강법 ▶ 경사 하강법 알고리즘을 이해하고 대량의 데이터에서 분류 모델을 훈련하기
학습 목표
- 경사 하강법 알고리즘을 이해하고 대량의 데이터에서 분류 모델을 훈련하는 방법을 배웁니다.
점직적인 학습 = 온라인 학습
- 앞서 훈련한 모델을 버리지 않고 새로운 데이터에 대해서만 조금씩 더 훈련하는 방법
- 대표적인 점진적 학습 알고리즘
- 확률적 경사 하강법(Stochastic Gradient Descent)
- 대표적인 점진적 학습 알고리즘
확률적 경사 하강법
- 확률적 = 무작위하게 = 랜덤하게
- 훈련 세트에서 랜덤하게 하나의 샘플을 고르는 것
- 에포크(epoch)
- 훈련 세트를 한 번 모두 사용하는 과정
- 샘플 선택 수에 따라
- 확률적 경사 하강법: 1개의 샘플을 사용해 경사 하강법 수행
- stochastic gradient descent
- 미니배치 경사 하강법: 여러 개의 샘플을 사용해 경사 하강법 수행
- minibatch gradient descent
- 배치 경사 하강법: 전체 샘플을 사용해 경사 하강법 수행
- batch gradient descent
- 확률적 경사 하강법: 1개의 샘플을 사용해 경사 하강법 수행
- 경사 하강법 ⇒ 신경망 알고리즘에 필수!
손실 함수(loss function)
- 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준
- 샘플 하나에 대한 손실 정의
- 분류에서의 손실 함수
- 이진 분류
- 로지스틱 손실 함수(logtistic loss function) = 이진 크로스엔트로피 손실 함수(binary cross-entropy loss function)
- 양성 클래스(타깃 = 1) 일 때: -log(예측 확률)
- 음성 클래스(타깃 = 0) 일 떄: -log(1-예측 확률)
- 로지스틱 손실 함수(logtistic loss function) = 이진 크로스엔트로피 손실 함수(binary cross-entropy loss function)
- 다중 분류
- 크로스엔트로피 손실 함수(cross-entropy loss function)
- 이진 분류
- 회귀에서의 손실 함수
- 평균 절댓값 오차: 타깃에서 예측을 뺀 절댓값을 모든 샘플에 평균한 값
- 평균 제곱 오차(mean squared error): 타깃에서 예측을 뺀 값을 제곱한 다음 모든 샘플에 펴균한 값
- 작을수록 좋은 모델
비용 함수(cost function)
- 훈련 세트에 있는 모든 샘플에 대한 손실 함수의 합
SGDClassifier
- OvR(One versus Rest)
- 다중 분류일 경우 SGDClassifier에 loss=’log’로 지정하면 클래스마다 이진 분류 모델을 만듦.
- partial_fit()
- 모델을 이어서 훈련
- 미니배치 경사 하강법이나 배치 하강법 제공 X
- 회귀 모델에서는?
- SGDRegressor 사용
- loss 매개변수
- default = ‘hinge’
- 힌지 손실은 서포트 벡터 머신(support vector machine)에서 사용
- default = ‘hinge’
에포크와 과대/과소적합
- 에포크에 따라 과대적합 혹은 과소적합이 될 수 있다.
- 따라서, 우리는 모델의 정확도가 가장 적합한 지점을 찾아야 한다.
- 조기 종료(early stopping)
- 과대 적합이 시작하기 전에 훈련을 멈추는 것
- partial_fit() 메서드만 사용하려면 훈련 세트에 있는 전체 클래스의 레이블을 partial_fit() 메서드에 전달해주어야 함.

 012
012
scikit-learn
- SGDClassifier: 확률적 경사 하강법을 사용한 분류 모델
- loss 매개변수는 확률적 경사 하강법으로 최적화할 손실 함수 지정
- default = ‘hinge’
- 로지스틱 회귀를 위해서는 loss=’log’
- penalty 매개변수는 규제의 종류 지정
- default = ‘l2’
- l1 = L1 규제(라쏘 방식)
- l2 = L2 규제(릿지 방식)
- default = ‘l2’
- max_iter 매개변수는 에포크 횟수 지정
- default = 1000
- tol 매개변수는 반복을 멈출 조건 지정
- default = 0.001
- n_iter_no_change 매개변수에서 지정한 에포크 동안 tol 만큼 줄어들지 않으면 알고리즘 중단
- default = 5
- loss 매개변수는 확률적 경사 하강법으로 최적화할 손실 함수 지정
- SGDRegressor: 확률적 경사 하강법을 사용한 회귀 모델
- loss 매개변수는 손실 함수 지정
- default = ‘squared_loss’
- 제곱 오차
- default = ‘squared_loss’
- 다른 매개변수는 SGDClassifier과 동일.
- loss 매개변수는 손실 함수 지정
확인 문제
- 다음 중 표준화 같은 데이터 전처리를 수행하지 않아도 되는 방식으로 구현된 클래스는 무엇인가요?
- 정답: 4번 / SGDClassifier
- 경사 하강법 알고리즘의 하나로 훈련 세트에서 몇 개의 샘플을 뽑아서 훈련하는 방식은 무엇인가요?
- 정답: 3번 / 미니배치 경사 하강법
혼공학습단 3주차 학습 소감
다양한 알고리즘이라 하여, 겁부터 난 것이 사실이다. 아무리 전공자이지만, 알고리즘은 참으로 친해지기 어려운 과목 중 하나였다. 하지만, 인공지능 모델 학습에서는 알고리즘에 대한 이해만 갖춰져 있다면 필요한 알고리즘 라이브러리 혹은 클래스를 가져다 쓰기만 하면 되므로, 정말 편하다는 사실을 알 수 있었다. (이것은 마치 React의 라이브러리와도 같은 느낌이랄까?!)
이전 주차에서는 이진 분류에서 다중 분류로 학습 모델 개념을 확장했다면 금주에는 모델을 이어서 훈련한다는 개념을 새롭게 알 수 있었다.
- fit() 대신 partial_fit()
이 밖에도 1. 경사 하강법 알고리즘, 2. epoch, 3. 손실/비용 함수에 대해서도 확실히 알 수 있었다.
- 경사 하강법 알고리즘
- 확률적 경사 하강법: 1개 샘플
- 미니배치 경사 하강법: 여러 개 샘플
- 배치 경사 하강법: 전체 샘플
- epoch
- 1 epoch: 경사 하강법 알고리즘에서 전체 샘플을 모두 사용하는 경우
- 손실/비용 함수
- 손실 함수: 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준이자, 샘플 하나에 대한 손실 정의
- 비용 함수: 훈련 세트에 있는 모든 샘플에 대한 손실 함수의 합
인공지능 어렵게만 느껴졌는데, 마치 경사 하강법 알고리즘처럼 점진적인 학습을 통해 배우고 정리하는 과정을 거치다보니 점점 길이 보이는 듯하다.
손 코딩 자료
반응형